验证集、测试集的区别及分割方法
在看《机器学习》的时候发现测试集与验证集的概念有些模糊,就上网去搜索了各种解释,还没有全部阅读消化,整理如下以便之后再看。
参考
⭐What is the Difference Between Test and Validation Datasets?
⭐What is the difference between test set and validation set?-StackExchange
验证集
当我们的模型训练好之后,我们并不知道他的表现如何。这个时候就可以使用验证集(Validation Dataset)来看看模型在新数据(验证集和测试集是不同的数据)上的表现如何。同时通过调整超参数,让模型处于最好的状态。

验证集有2个主要的作用:
- 评估模型效果,为了调整超参数而服务
- 调整超参数,使得模型在验证集上的效果最好
同时验证集在训练过程中还可以用来监控模型是否发生过拟合,一般来说验证集表现稳定后,若继续训练,训练集表现还会继续上升,但是验证集会出现不升反降的情况,这样一般就发生了过拟合。所以验证集也用来判断何时停止训练。
说明:
- 验证集不像训练集和测试集,它是非必需的。如果不需要调整超参数,就可以不使用验证集,直接用测试集来评估效果。
- 验证集评估出来的效果并非模型的最终效果,主要是用来调整超参数的,模型最终效果以测试集的评估结果为准。
测试集
训练集直接参与了模型调慘的过程,显然不能用来反映模型真实的能力,这样一些 对课本死记硬背的学生(过拟合)将会拥有最好的成绩,显然不对。同理,由于验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型,就像刷题库的学生也不能算是学习好的学生是吧。所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力。
但是仅凭一次考试就对模型的好坏进行评判显然是不合理的,所以就要用到交叉验证法。
通过测试集(Test Dataset)来做最终的评估。通过测试集的评估,我们会得到一些最终的评估指标,例如:准确率、精确率、召回率、F1等,用来近似估计模型的泛化能力。此时假设有两个不同的机器学习模型,犹豫不决的时候,可以通过训练两个模型,然后对比他们在测试数据上的泛化误差,选择泛化能力强的模型。
二者区别
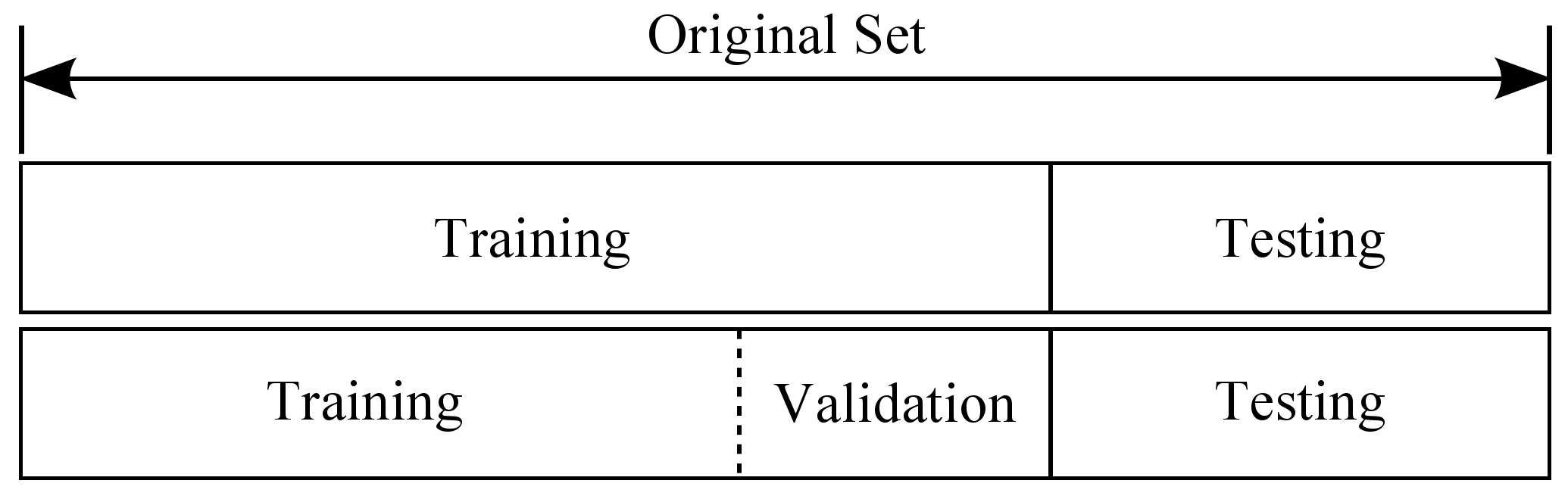
测试集是用于从几个不同模型中选出最好的,而验证集则是通过调参将某一模型调整为最好的状态。
若直接拿测试集去调整超参数,那么可以直接将模型调整到测试集上的最佳,甚至误差为0,但这样的模型放在真实环境中表现可能会很差,因为实际上调参的过程也是“训练”模型的过程。这种现象叫做信息泄露。
我们使用测试集作为泛化误差的近似,所以不到最后是不能将测试集的信息泄露出去的,就好比考试一样,我们平时做的题相当于训练集,测试集相当于最终的考试,我们通过最终的考试来检验我们最终的学习能力,将测试集信息泄露出去,相当于学生提前知道了考试题目,那最后再考这些提前知道的考试题目,当然代表不了什么,你在最后的考试中得再高的分数,也不能代表你学习能力强。而如果通过测试集来调节模型,相当于不仅知道了考试的题目,学生还都学会怎么做这些题了(因为我们肯定会人为的让模型在测试集上的误差最小,因为这是你调整超参数的目的),那再拿这些题考试的话,人人都有可能考满分,但是并没有起到检测学生学习能力的作用。原来我们通过测试集来近似泛化误差,也就是通过考试来检验学生的学习能力,但是由于信息泄露,此时的测试集即考试无任何意义,现实中可能学生的能力很差。所以,我们在学习的时候,老师会准备一些小测试来帮助我们查缺补漏,这些小测试也就是要说的验证集。我们通过验证集来作为调整模型的依据,这样不至于将测试集中的信息泄露。
Peeking is a consequence of using test-set performance to both choose a hypothesis and evaluate it. The way to avoid this is to really hold the test set out—lock it away until you are completely done with learning and simply wish to obtain an independent evaluation of the final hypothesis. (And then, if you don’t like the results … you have to obtain, and lock away, a completely new test set if you want to go back and find a better hypothesis.)
If the test set is locked away, but you still want to measure performance on unseen data as a way of selecting a good hypothesis, then divide the available data (without the test set) into a training set and a validation set.
也就是说我们将数据划分训练集、验证集和测试集。在训练集上训练模型,在验证集上评估模型,一旦找到的最佳的参数,就在测试集上最后测试一次,测试集上的误差作为泛化误差的近似。
划分数据集
对于留出法:
- 对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
- 对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
- 超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。
交叉验证法(cross-validation):
常用的是留少部分做测试集。然后对其余N个样本采用K折交叉验证法。就是将样本打乱,然后均匀分成K份,轮流选择其中K-1份训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和再做平均作为选择最优模型结构的依据。特别的K取N,就是留一法(leave one out)。

理解:
交叉验证法既可以用来区分训练集和测试集,也可以用来区分训练数据和验证数据。