汉字编码介绍
参考资料
1. 汉字以前为什么无法在计算机内表示
刚开始时,计算机内对人类语言的编码只停留在英文字母和一些其它字符上,总共128个被称为ASCII美国信息交换标准代码,中文汉字无法通过这些符号表示出来,也因此无法被计算机识别。在计算机内表示汉字需要有一套完整的汉字字符集和编码方式。
2. 梳理汉字的字符编码方式
常见的汉字字符集编码如下:
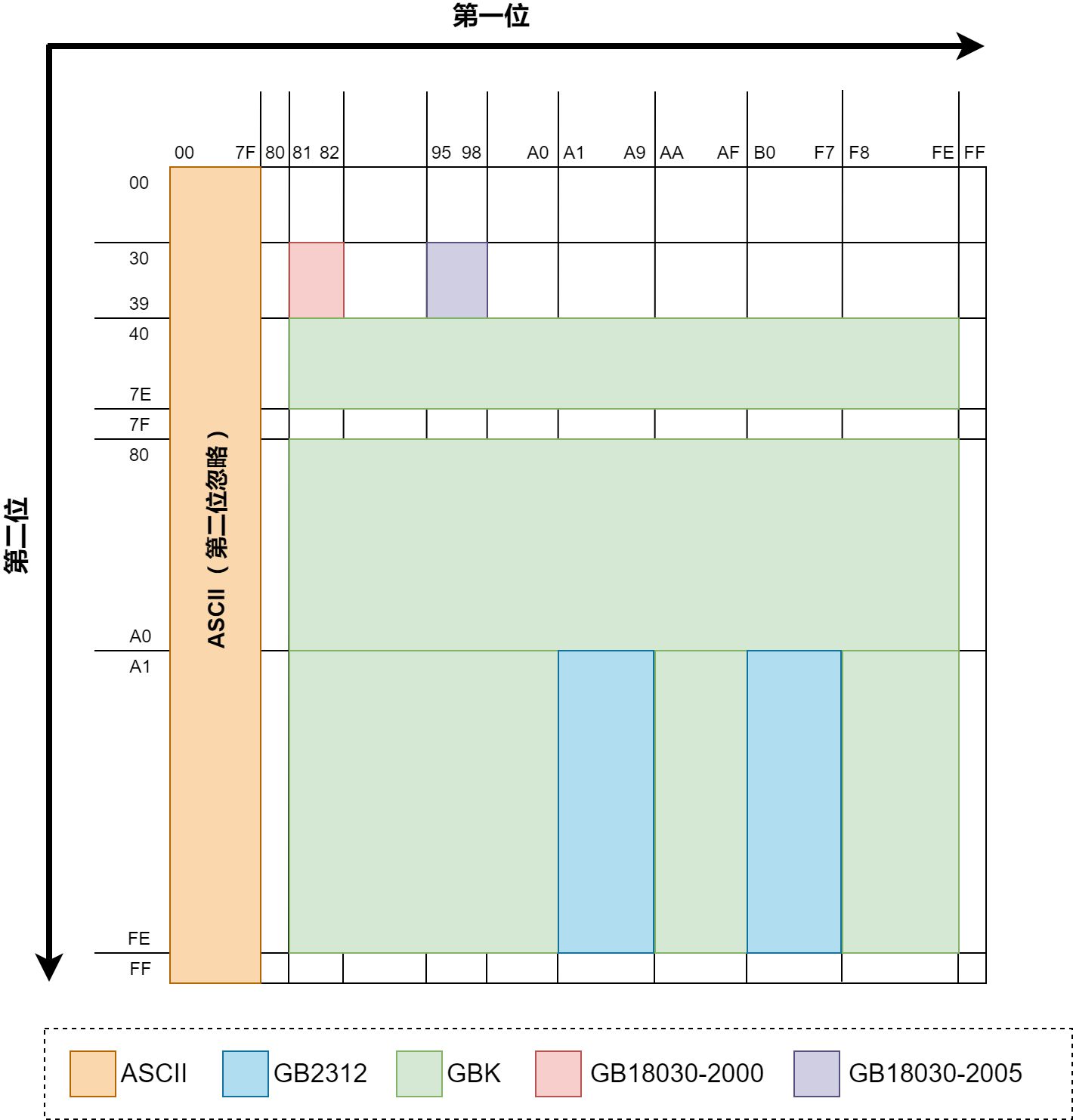
GB2312编码:1981年5月1日发布的简体中文汉字编码国家标准。国标码共收进标准字符7445个。其中一级汉字3755个,二级汉字3008个,共计6763个汉字。 由于汉字的字符多,一个字节即8位二进制代码不足以表示所有的常用汉字。同时为了不与西文的ASCII码混淆,汉字国标码的每个汉字或符号都使用2个字节(16位二进制)代码来表示。
GB2312编码表有个值得注意的点,这个表中也有一些数字和字母,与ASCII里面的字母非常像。例如A3B2对应的是数字2(如下图),但是ASCII里面50(十进制)对应的也是数字2。他们的区别就是输入法中所说的“半角”和“全角”。全角的数字2占两个字节。通常,我们在打字或编程中都使用半角,即ASCII来编写数字或英文字母。特别是编程中,如果写全角的数字或字母,编译器很有可能不认识。
BIG5编码:台湾地区繁体中文标准字符集,采用双字节编码,共收录13053个中文字,1984年实施。
GBK编码:1995年12月发布的汉字编码国家标准,是对GB2312编码的扩充,对汉字采用双字节编码。GBK字符集共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
GB18030编码:2000年3月17日发布的汉字编码国家标准,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录27484个汉字。GB18030字符集采用单字节、双字节和四字节三种方式对字符编码。兼容GBK和GB2312字符集。
几个标准之间的兼容问题:
GB2312,GBK,GB18030都是采取了固定长度的办法来解决字符分隔问题。GBK和GB2312比ASCII多出来的字都是2bytes,GB18030比GBK多出来的字都是4bytes。
不同编码的前2字节值域:
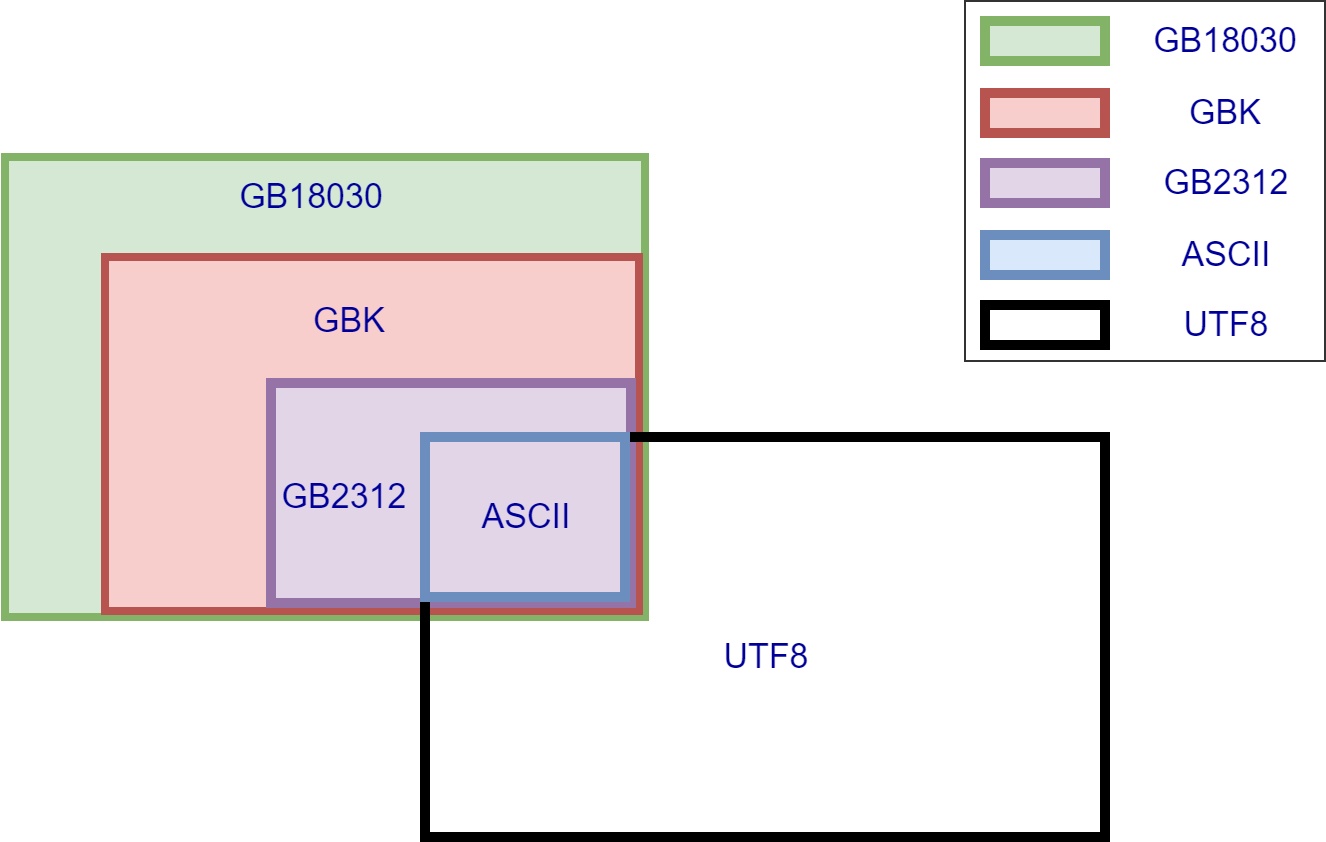
Unicode编码:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。Unicode采用四个字节为每个字符编码。
UTF-8和UTF-16编码:Unicode编码的转换格式,可变长编码,相对于Unicode更节省空间。UTF-16的字节序有大尾序(big-endian)和小尾序(little-endian)之别。
3. “汉字信息处理与印刷革命”在“二十世纪我国重大工程技术成就”排列第二
背景:20世纪70年代的中国,采用的仍是“以火熔铅、以铅铸字”的铅字排版印刷。这种方式能耗大、劳动强度高、环境污染严重,且出版印刷能力极低。而彼时,西方已率先采用“电子照排技术”,即利用计算机控制实现照相排版。要跟上世界信息化发展步伐,汉字必须与计算机相结合,否则中国将难以进入信息化时代。
看法:汉字进入计算机的过程是中国重新回到世界舞台、融入世界过程的一个缩影,汉字的成功处理与印刷标志着中国一个里程碑式的成功,同时它也大大加速了知识的传播,评选结果说明了它在中国历史上的重要性毋庸置疑。汉字处理与印刷听着简单,实则不然:英文仅26个字母,但汉字的常用字就好几千个,印刷中还有多种字体和大小不同的字号变化,要想在计算机中建立汉字字库,储存量巨大,与当时计算机水平完全不符,汉字字形信息的计算机存储和复原是一个世界性难题。
相关知识
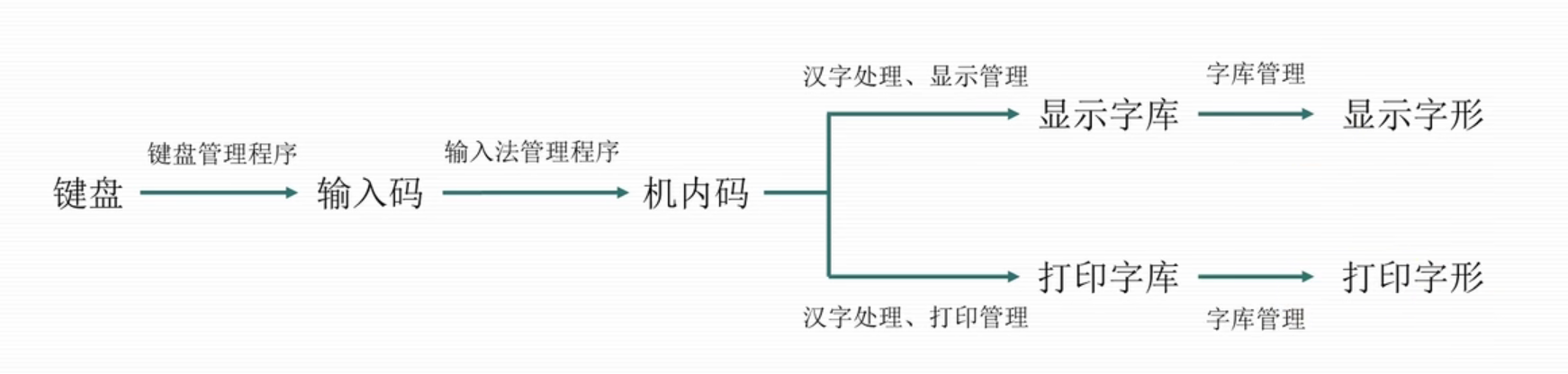
汉字的转换过程
内码与外码
内码:用来在计算机中存储、处理与传输汉字。在计算机中双字节汉字与单字节西文字符混合使用、处理,汉字编码的各个字节若不予以特别标识,就会与单字节的ASCII码混淆不清;为此,将标识汉字的两个字节编码的最高位置为1,这种最高位为1的双字节汉字编码就是中国大陆普遍采用的汉字机内码,简称内码。
外码:汉字的输入码。分为纯形码(五笔)、纯音码(拼音)、音形结合码和序号码(如区位码,无重码)。
汉字的显示原理
- 从键盘输入的汉字经过键盘管理模块,变换成机内码。
- 然后经字模检索程序,查到机内码对应的点阵信息在字模库的地址。
- 从字库中检索出该汉字点阵信息。
- 利用显示驱动程序将这些信息送到显示卡的显示缓冲存储器中。
- 显示器的控制器把点阵信息整屏顺次读出,并使每一个二进制位与屏幕的一个点位相对应,就可以将汉字字形在屏幕上显示出来。
使用区位码获得汉字在字库中的具体位置:
(94*(区号-1) + 位号-1) * 一个汉字字模占用的字节数
字符集编码
字符集编码是指对多个字符(通常在几十到几万个不等)进行整合封装成一个文件所使用的编码,外部程序通过这种编码就可以从字符集文件中调用指定的字符。我们常见的计算机字体文件就使用了字符集编码,通过输入法输入文字或者浏览网页时都会通过指定的字符集编码从字体文件中调用字符。
国标码与区位码的区别
区位码是四位的十进制数字,是GB2312国标码中的分区表示方法,区位码的前两位数是“区号”,后两位数是“位号”。 区号和位号分别加上160,再分别转换成十六进制数,就成为四位的十六进制GB2312国家标准编码(简称国标码)。
内码、国标码、区位码三者的关系
高字节内码=高字节国标码+80H=区码+20H+80H
低字节内码=低字节国标码+80H=位码+20H+80H
字符集与编码方式的区别
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
当一个中英文夹杂的字符串输入到电脑的时候,计算机是如何知道它到底是什么的?就像0100 1110 0000 0011,它到底是表示的是0100 1110和0000 0011两个ASCII字符,还是汉字”七“?计算机并不知道。所以就需要一套规则来告诉计算机,到底该按照什么来解析。这些规则,就是字符编码格式。
例如,Unicode赋予了全世界所有文字和符号一个独一无二的数字编号,UTF8所做的事情就是把这个数字编号表示出来。
94个区?
有好事者问:为什么是94个区呢?94也不是2的n次幂的结果啊?
这个问题问得好,很多人刚接触汉字编码时都对这个数字一头雾水。但是其实这个数字也是在尽可能的范围内取得最大值。还记得前文ASCII中提到的控制字符吗?ASCII的前32个字符就是控制字符,实际上第128个字符也是控制码(DEL,删除),而区位又是从01开始计数,所以128-32-1-1=94。这就选择94这个看似很钦定,实际上很有人生哲理的数字的原因。
乱码问题
20世纪70年代的中国,采用的仍是“以火熔铅、以铅铸字”的铅字排版印刷。在排版车间,捡字工人需在铅字架间来回走动,把文稿所需要的铅字一个个从架子上找出来。一个熟练工人每天要托着铅盘来来回回走上十几里路,双手总会因捡字而变得漆黑。
这种方式能耗大、劳动强度高、环境污染严重,且出版印刷能力极低,出书一般要在出版社压上一年左右。
据不完全统计,当时我国铸字耗用的铅合金达20万吨,铜模200多万副,价值人民币60亿元。而彼时,西方已率先采用“电子照排技术”,即利用计算机控制实现照相排版。
要跟上世界信息化发展步伐,汉字必须与计算机相结合,否则中国将难以进入信息化时代。
为改变这种落后状况,1974年,我国设立“汉字信息处理系统工程”,即“748工程”。这让当时在北大无线电系任助教、已病休10多年的王选,找到了奋斗方向。
当时,国外流行的是第二代、第三代照排机,但王选通过反复分析比较,认为它们都不具前途,且在当时中国存在巨大技术困难。他决定直接研制世界尚无成品的第四代激光照排系统,即在电脑控制下将数字化存储的字模用激光束在底片上感光成字、制版印刷。
这个重要决定,使日后的中国印刷业从铅板印刷直接步入激光照排阶段,跨越了国外照排机40年的发展历史。
研究汉字激光照排系统的首要难题,就是要将庞大的汉字字形信息存储进计算机中。然而,要让计算机接纳汉字,谈何容易。
英文仅26个字母,但汉字的常用字就好几千个,印刷中还有多种字体和大小不同的字号变化,要想在计算机中建立汉字字库,储存量巨大,与当时计算机水平完全不符。
如何用最少的信息描述汉字笔画?1975年,基于计算数学的研究背景,王选绞尽脑汁,最终想到用“轮廓加参数”的数学方法来描述字形。这一方法可使字形信息压缩500倍至1000倍,并实现变倍复原时的高速和高保真。汉字字形信息的计算机存储和复原的世界性难题被攻克。
1976年,王选的技术方案得到国家支持,“汉字精密照排系统”研制任务下达北大,王选成为技术总负责人。