语言消歧
在词义、句义、篇章含义层次都会出现语言根据上下文语义不同的现象,消歧即指根据上下文确定对象语义的过程。词义消歧即在词语层次上的语义消歧。语义消歧/词义消歧 是自然语言处理任务的一个核心与难点,影响了几乎所有任务的性能,比如搜索引擎、意见挖掘、文本理解与产生、推理等。
在语言学长期发展的过程中,语言本身积累了许多一词多义的用法。语言的产生是多方面共同作用的结果。语言的使用是不断变化的,一个词在发展中有许多具体的意思,现在通用的还有一些意思。不同地区可能对一个词有不同 的用法,不同的行业对一个词也会不同,甚至不同群体、不同个人、不同语气都会有自己的特殊的解读意思。语义消歧是一种语言理解的方式,一方面我们要理解通用词语一词多义的含义及应用,另一方面,还要考虑到具体场景,运用相关知识库、语料训练来增加一词多义的性能。
词性标注与词义消歧是相互关联的两个问题。二者都要依赖上下文来标注,但是词性标注比语义消歧要简单以及成功。原因主要是词性标注的标注集合是确定的,而语义消歧并没有,并且量级要大的多;词性标注的上下文依赖比语义消歧要短。
WSD应用
- 机器翻译
- 信息检索 IR
- 文本挖掘与信息提取 IE
- 词典编纂
1. 举例说明消歧在英文的tokenization工具中是如何实现的。
基本方法:
基于字典的方法(如Lesk Algorithm)
基于语义定义的消歧。如果词典中对W的 第i种定义 包含 词汇Ei,那么如果在一个包含W的句子中,同时也出现了Ei,那么就认为 在该句子中 W的语义应该取词典中的第i种定义。
基于类义辞典的消歧。词的每个语义 都定义其对应的主题或范畴(如“网球”对应的主题是“运动”),多个语义即对应了多个主题。如果W的上下文C中的词汇包含多个主题,则取其频率最高的主题,作为W的主题,确定了W的主题后,也就能确定其对应的语义。
基于双语对比的消歧。即把一种语言作为另一种语言的定义。例如,为了确定“interest”在英文句子A中的含义,可以利用句子A的中文表达,因为interest的不同语义在中文的表达是不同的。如果句子A对应中文包含“存款利率”,那么“interest”在句子A的语义就是“利率”。如果句子A的对应中文是“我对英语没有兴趣”,那么其语义就是“兴趣”。
监督方法(如支持向量机、基于内存的学习、贝叶斯分类器、基于统计的学习)
利用带注释的语料库,上下文被认为是词的特征,而知识和推理被忽略半监督方法
从种子数据进行引导无监督方法
假设相似的含义发生在相似的上下文中。通过对上下文相似性的某种度量对词的含义进行聚类。基于深度学习
1.1 NLTK(): Lesk Algorithm
单词的定义与当前上下文之间的度量重叠
- It uses the definitions of the ambiguous word. Given an ambiguous word and the context in which the word occurs, Lesk returns a Synset with the highest number of overlapping words between the context sentence and different definitions from each Synset.
- Lesk’s algorithm disambiguates a target word by selecting the sense whose dictionary gloss shares the largest number of words with the glosses of neighboring words.
Context:
- It requires a sense inventory with word sense definitions.
- It compares the overlap between a word’s text window and the words in the word sense definition.
- It selects the word sense with the largest overlap.
- It can be extended by expanding the words that will be compared. For example, by means of including similar words in WordNet. (Banerjee & Pedersen, 2002)
实现:
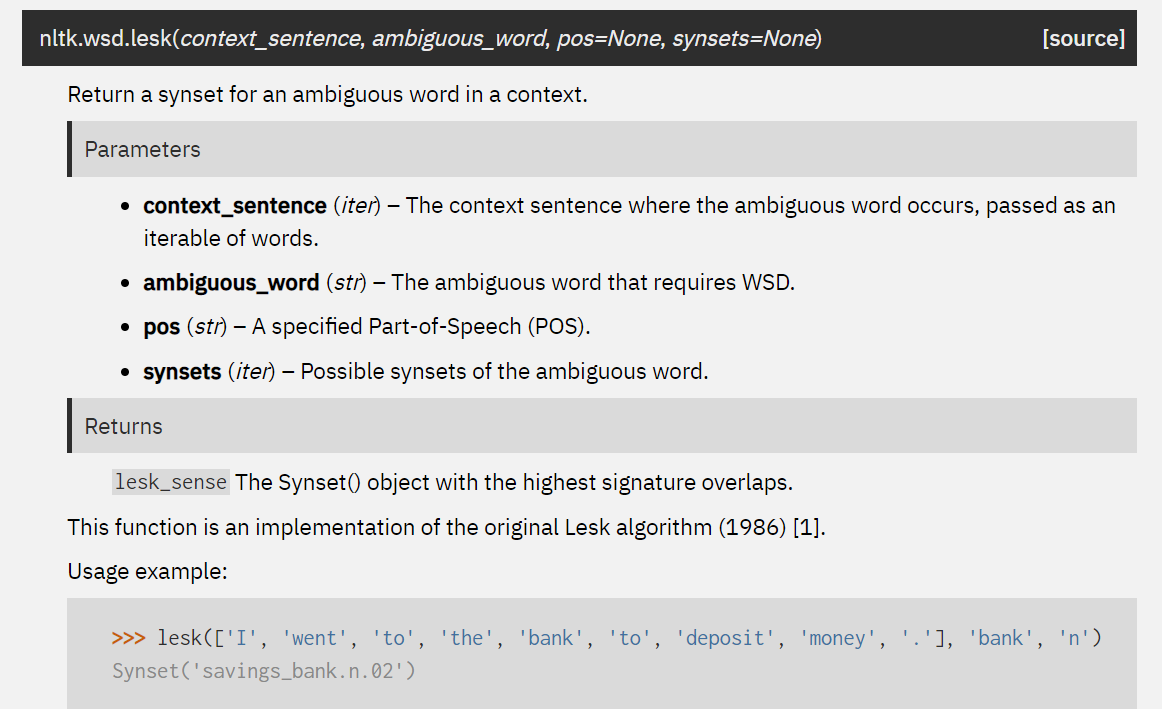
source:
1 | from nltk.corpus import wordnet |
1.2 pywsd中的三种语义消歧的实现
Lesk algorithms
- Original Lesk (Lesk, 1986)
- Adapted/Extended Lesk (Banerjee and Pederson, 2002/2003)
- Simple Lesk (with definition, example(s) and hyper+hyponyms)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def simple_lesk(context_sentence: str, ambiguous_word: str,
pos: str = None, lemma=True, stem=False, hyperhypo=True,
stop=True, context_is_lemmatized=False,
nbest=False, keepscore=False, normalizescore=False,
from_cache=True) -> "wn.Synset":
"""
Simple Lesk is somewhere in between using more than the
original Lesk algorithm (1986) and using less signature
words than adapted Lesk (Banerjee and Pederson, 2002)
:param context_sentence: String, sentence or document.
:param ambiguous_word: String, a single word.
:param pos: String, one of 'a', 'r', 's', 'n', 'v', or None.
:return: A Synset for the estimated best sense.
"""
# Ensure that ambiguous word is a lemma.
ambiguous_word = lemmatize(ambiguous_word, pos=pos)
# If ambiguous word not in WordNet return None
if not wn.synsets(ambiguous_word):
return None
# Get the signatures for each synset.
ss_sign = simple_signatures(ambiguous_word, pos, lemma, stem, hyperhypo, stop,
from_cache=from_cache)
# Disambiguate the sense in context.
context_sentence = context_sentence.split() if context_is_lemmatized else lemmatize_sentence(context_sentence)
return compare_overlaps(context_sentence, ss_sign, nbest=nbest,
keepscore=keepscore, normalizescore=normalizescore)- Cosine Lesk (use cosines to calculate overlaps instead of using raw counts)
Maximizing Similarity (see also, Pedersen et al. (2003))
- Path similarity (Wu-Palmer, 1994; Leacock and Chodorow, 1998)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def similarity_by_path(sense1: "wn.Synset", sense2: "wn.Synset", option: str = "path") -> float:
"""
Returns maximum path similarity between two senses.
:param sense1: A synset.
:param sense2: A synset.
:param option: String, one of ('path', 'wup', 'lch').
:return: A float, similarity measurement.
"""
if option.lower() in ["path", "path_similarity"]: # Path similarities.
return max(wn.path_similarity(sense1, sense2, if_none_return=0),
wn.path_similarity(sense2, sense1, if_none_return=0))
elif option.lower() in ["wup", "wupa", "wu-palmer", "wu-palmer"]: # Wu-Palmer
return max(wn.wup_similarity(sense1, sense2, if_none_return=0),
wn.wup_similarity(sense2, sense1, if_none_return=0))
elif option.lower() in ['lch', "leacock-chordorow"]: # Leacock-Chodorow
if sense1.pos != sense2.pos: # lch can't do diff POS
return 0
return wn.lch_similarity(sense1, sense2, if_none_return=0)- Information Content (Resnik, 1995; Jiang and Corath, 1997; Lin, 1998)
1 | def max_similarity(context_sentence: str, ambiguous_word: str, option="path", |
2. 从最长匹配到最大频率分词,体现了工程实践中的普遍规律。
规律:从完全的机械性的、工程性的问题转化为可以基于经验解决的问题。
从最长匹配到最大频率分词,分词任务已经从单纯的“算法”上升到了“建模”,即利用统计学方法结合大数据挖掘,对“语言”进行建模;从仅仅是词的层面上升到了语义的层面。
最长匹配分词中只需要一个完备的词典就可以完成分词任务,但这种切分结果与实际生活的关联并不太大;而最大频率分词使用到了统计方法,通过统计语料将人们日常生活中使用到的词、句子的形式的这个知识融入了模型中,去解决类似场景中的问题。个人理解最大频率分词更像是加入了先验概率(经验)得到的结果。
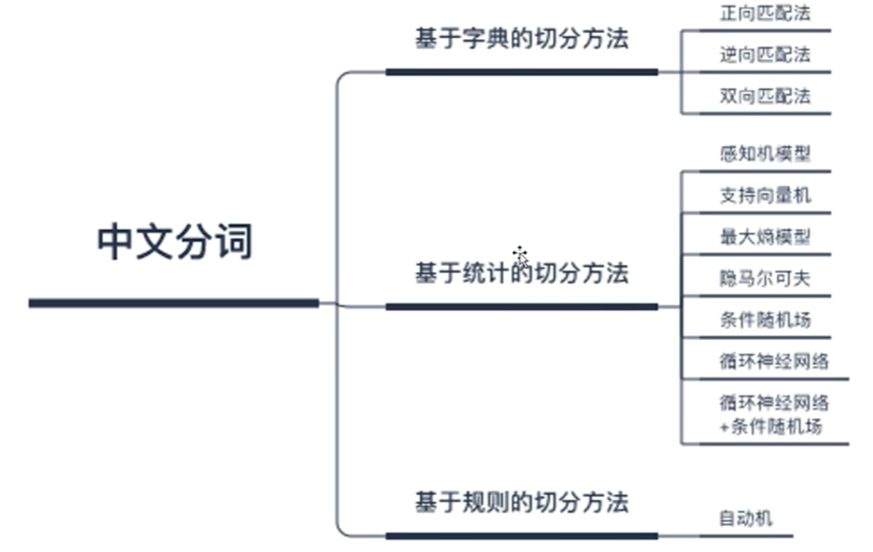
3. 站在工程技术角度,tokenization对于NLP的意义。
A tokenizer breaks unstructured data and natural language text into chunks of information that can be considered as discrete elements. The token occurrences in a document can be used directly as a vector representing that document.
This immediately turns an unstructured string (text document) into a numerical data structure suitable for machine learning. They can also be used directly by a computer to trigger useful actions and responses. Or they might be used in a machine learning pipeline as features that trigger more complex decisions or behavior.
- 词是一个比较合适的粒度:通过分析词语的意思能够得到文本的意思,单字很多时候表达不了语义,而词语能够承载语义。
- 切断上下文耦合,降低词序的影响。让各组合之间的耦合性降低,以组合为特征,使其更接近我们的假设。
- 将复杂问题转化为数学问题:文本都是一些「非结构化数据」,我们需要先将这些数据转化为「结构化数据」,结构化数据就可以转化为数学问题了,而分词就是转化的第一步。
4. 证明最长匹配分词的合理性。
intuition:
最大匹配原则:使切分出来的词尽可能地少。
切分出来的词越多,表达的含义就越丰富,也会导致准确理解这句话的难度加大。
若在字典中存在,自然语言处理 与 自然/语言/处理 相比能简单直接表达意思。
证明:
- 首先,由于最长匹配分词是基于词典的方法,分出来的词不会出错。(不考虑歧义情况)
- 其次,最长匹配的算法也符合最大匹配原则,切分不会太细导致失去意义,且能给后续操作提供一个可能达到较高效率的分词序列。
- 最后,它能够通过在词典中添加新词来提高准确率,而不需要庞大的输入文本。
相关资料
- Tokenization in NLP – Types, Challenges, Examples, Tools
- 词义消歧 wikipedia
- Lesk algorithm wikipedia
- 达观数据:综述中英文自然语言处理的异和同
- 词义消岐(WSD)的简介与实现
- 基于改进的 Lesk 算法的词义排歧算法.王永生
- WORD SENSE DISAMBIGUATION: A SURVEY.Alok Ranjan Pal and Diganta Saha
- 分词 – Tokenization
- 中文分词综述
- 关于nlp:Python中的词义消歧算法
- Python Implementations of Word Sense Disambiguation (WSD) Technologies.
- nltk.wsd module documentation
- 漫话中文自动分词和语义识别(上):中文分词算法
- 深度长文:中文分词的十年回顾
- 中文分词技术及在 58 搜索的实践
- 中文分词技术详解